I want your feedback to make the book better for you and other readers. If you find typos, errors, or places where the text may be improved, please let me know. The best ways to provide feedback are by GitHub or hypothes.is annotations.
Opening an issue or submitting a pull request on GitHub: https://github.com/isaactpetersen/Principles-Psychological-Assessment
Adding an annotation using hypothes.is.
To add an annotation, select some text and then click the
symbol on the pop-up menu.
To see the annotations of others, click the
symbol in the upper right-hand corner of the page.
Chapter 18 Objective Personality Testing
18.1 Overview of Personality Tests
There are two main types of personality tests: objective personality tests and projective personality tests. Of course, no measure is truly “objective” but some measures are more or less so. In a so-called objective personality test (or structured personality test), a stimulus is presented to a respondent, who makes a closed-ended (constrained) response, such as True/False or Likert ratings. Examples of objective personality or symptomatology tests include the Minnesota Multiphasic Personality Inventory (MMPI) and the Beck Depression Inventory (BDI). In a projective personality test, an ambiguous stimulus is presented to a respondent, who is asked to make an open-ended response. Examples of projective personality tests include the Rorschach Inkblot Test and the Thematic Apperception Test (TAT). Projective tests have largely fallen by the wayside now, but it is still helpful to think about their potential advantages. Projective tests are described in further detail in Chapter 19.
18.1.1 Projective Personality Tests
In a projective personality test, the client’s response is not limited. Projective personality tests were designed from a psychodynamic perspective, and they are supposed to have limitless variability and therefore a freer access to the client’s internal world. However, Card V of the Rorschach Inkblot Test looks like a moth or a bat, and around 90% of respondents likely give that response (Wiggins, 1973), so projective tests are not completely limitless. Projective personality tests are designed to have ambiguous content. This is, in part, to make them hard to figure out what is being assessed. That is, they tend to have low face validity. However, even so-called objective personality tests can have items that are ambiguous and that function similarly to a projective test. For instance, one of the items on the original MMPI asks respondents whether they like mechanics magazines. But in modern times, many people have never looked at a mechanics magazine. So, it becomes like a Rorschach question because the client starts to think about other factors.
Scoring of projective tests does not rely on the client’s insight, so projective tests might get past social desirability of clients’ responses and potential defensiveness. Therefore, projective tests are potentially difficult to fake. Faking good means to present oneself as better (or in a more positive light) than one actually is, whereas faking bad means to present oneself as worse (or in a more negative light) than one actually is. Faking or feigning responses often happens for incentives due to external reasons. For instance, a client may want to fake good on a test if it allows them to get a job or to win custody of a child. By contrast, a client may want to fake bad to receive disability insurance or to be pronounced not guilty by reason of insanity.
As of 1995, the TAT and Rorschach were the #5 and #6 most widely used assessments, respectively, by clinical psychologists (Watkins et al., 1995). However, they and other projective techniques have lost considerable ground since then.
18.1.2 Objective Personality Tests
In contrast to projective personality tests, objective personality tests, the client’s responses are substantially constrained to the possible answers. Moreover, objective personality tests tend to be cheap and fast to administer, and they can be scored by computers now. In addition, objective tests have more reliable scoring than projective tests. It takes a very long time to score the Rorschach Inkblot Test, and it still has very low reliability. With an objective test, by contrast, scoring reliability approaches perfection. The earliest examples of objective personality tests were the MMPI and the Strong Vocational Interest Blank. The MMPI assesses personality, whereas the Strong Vocational Interest Blank assessed preferences for different jobs or professions. An overview of objective personality tests is provided by Wiggins (1973).
18.2 Example of an Objective Personality Test: MMPI
The MMPI is an example of a so-called “objective” personality test. But the MMPI and other objective personality tests are not truly objective. Consider an example of a True/False item from the MMPI: “I hardly ever notice my heart pounding and I am seldom short of breath”. The item is intended to assess somatic symptom disorder, with a response of “false” being more indicative of disorder. But there are other factors that could influence a person’s response to the question besides whether the person has somatic symptom disorder. Figure 18.1 depicts how a person’s response to the question could be influenced by several factors. A comorbidity of somatic symptom disorder could make it more likely that a person answers with a response of “false”, in line with somatic symptom disorder. In addition, a person’s insight ability may influence whether they answer with a response of “false”. Also, people who exercise more may experience a pounding heart and shortness of breath more frequently (i.e., while exercising), and therefore answer with a response of “false”. In sum, the item and the test as a whole is clearly not “objective” because constructs in the questions are not clearly defined. What does a “pounding heart” mean? How much is “hardly ever”? People may define “seldom” differently.
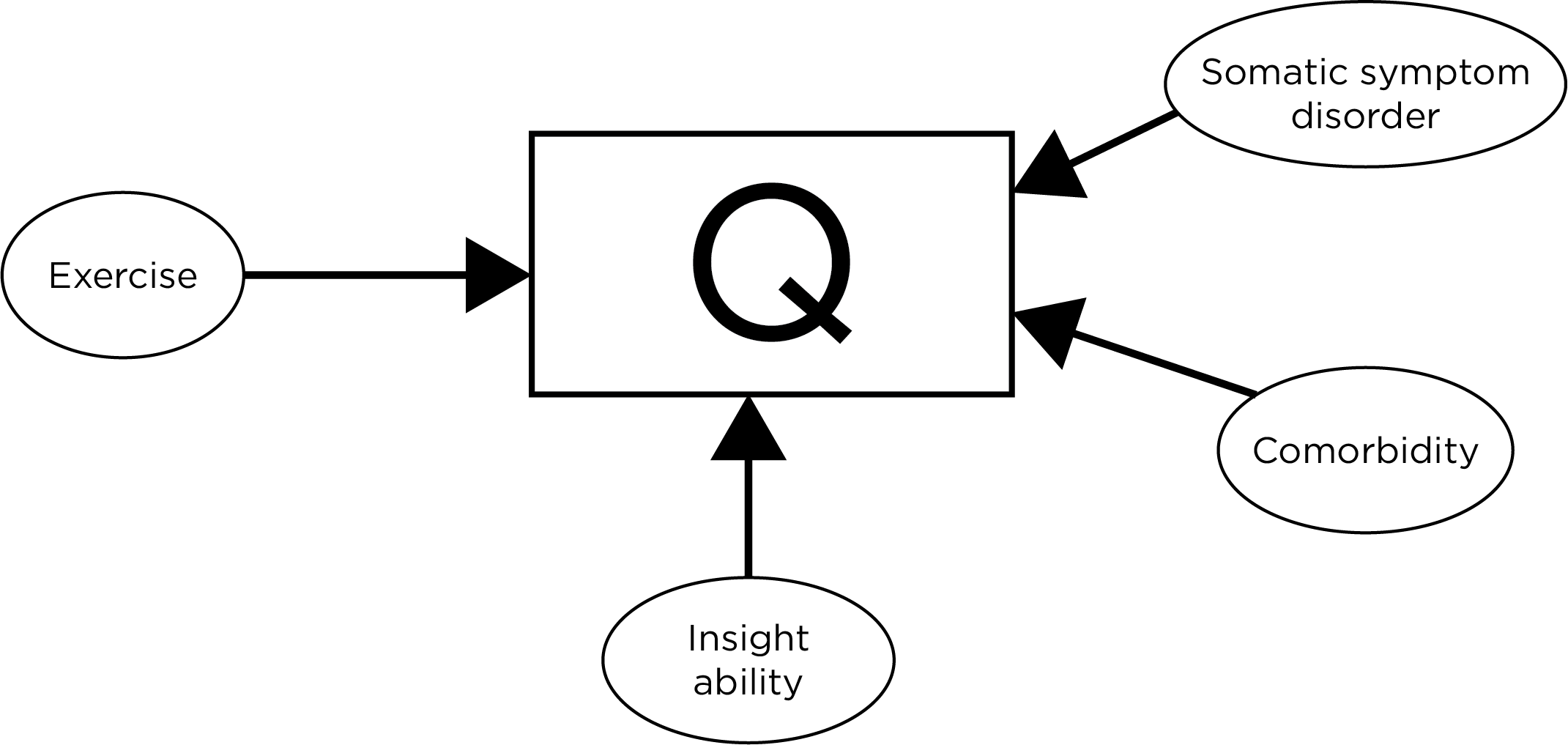
Figure 18.1: Various Factors That Could Influence a Respondent’s Answer to the True/False Question: “I hardly ever notice my heart pounding, and I am seldom short of breath”.
There are multiple forms of measurement error for a given item. For instance, there are situational sources of measurement error. Consider the item “I hardly ever notice my heart pounding, and I am seldom short of breath”. For example, how many stairs the participant climbed to get to the lab could influence their response to the question. Other situational factors could include whether they are dehydrated, whether they have a cold or are sick, and what they did over the past week. Another form of measurement error could result from the purpose of test taking. It is important to consider the purpose of the assessment. For example, if the assessment is for disability payments or to get a physical job, such as a firefighter, it may change a person’s answers. Response biases, such as social desirability, could also influence a person’s answers. In addition, memory limitations of the person could influence their responses.
There have been multiple versions of the MMPI. J. R. Graham et al. (2022) provide an overview of how the MMPI was developed. The original MMPI was developed using the external approach to scale construction. The second version of the MMPI (MMPI-2) placed greater emphasis on content validity of the items, on removing items with outdated or offensive language, and on updating the norms to be more representative. Later, restructured versions of the MMPI-2 were created, which became known as the MMPI-2-Restructured Forms (MMPI-2-RF). Evidence on the MMPI-2-RF is reviewed by Sellbom (2019). The latest version of the MMPI is the MMPI-3.
18.3 Problems with Objective True/False Measures
There are a number of problems with objective True/False measures. However, the problems are not necessarily unique to objective personality measures or to True/False measures.
One problem is related to the response biases of acquiescence and disacquiescence. Acquiescence occurs when the person agrees in response to items regardless of item content. Acquiescence occurs oftentimes when the participant is just going along because they think the experimenter may want them to have certain characteristics, therefore they often just say “TRUE” a lot. That is, they may want to please the investigators. Disacquiescence, by contrast, is when the person disagrees in response to the items regardless of item content. Disacquiescence is also called opposition bias. Disacquiescence may occur if the person does not think they have the disorder or problem of the characteristics being explored.
True/False measures, just like other questionnaire formats, are influenced by multiple sources of variation. In an objective personality test, there is a high demand on respondents. For instance, on the MMPI, respondents must be aware of recall over an unspecified period of time, which can cause confusion. The high demand on respondents can lead to inaccuracy of individuals’ reading of the items. Additional sources of information could influence the respondents’ answers to the item, “I hardly ever notice my heart pounding, and I am seldom short of breath”. Some respondents may be intoxicated while answering questions, which could influence physiological experiences. Some respondents may have comorbordities that influence their responses. Psychological and medical comorbidities could cause difficulty in interpreting the questions. For example, the respondent may wonder whether the investigator is inquiring about heart beating that reflects anxiety versus heart beating that reflects high blood pressure.
In addition, there are effort differences that influence people’s responding. There has been a recent resurgence in how to assess respondents’ effort. There are often limits to predicting phenomena due to individuals not putting effort into answering questions. Other potential sources of variation in an item could include psychopathology, stress, physical fitness, age, and gender. For instance, older people are more likely to notice shortness of breath because their lung capacity is less than what it used to be. Moreover, women are more likely to say “FALSE” to this item than men, but the item has less social desirability bias than some other items, so women could be putting in more effort and giving different responses than men.
In sum, lots of factors beyond the construct of interest can influence a response on an item. It is valuable to scan through your measures and consider what goes into a person’s answers. It is important to keep the content in mind of all things contributing to scores, and you should consider these potential factors when interpreting results!
Another problem with some questions is compound questions, also called double-barreled questions. Double-barreled questions following the structure: \(\text{T/F: X} + \text{Y}\). An example of a compound question is, “True or False: Cars should be faster and safer”. It is unclear which components of a compound question people are responding to. In conclusion, every objective test is partly projective—that is, the stimuli are interpreted in different ways by different people.
18.4 Approaches to Developing Personality Measures
There are three primary approaches to developing personality measures and other scales:
- An external approach to scale construction, also called an empirical approach or criterion-keyed approach
- A deductive approach to scale construction, also called a rational, theoretical, or intuitive approach
- An inductive approach to scale construction, also called an internal or item-metric approach
However, these approaches are not mutually exclusive and can be combined.
18.4.1 External Approach to Scale Contruction
The external approach to developing a personality measure is also called the empirical approach or the criterion-keyed approach. The external approach relies on an external criterion. In general, a criterion-keyed approach examines scores on items in relation to the criterion, and selects items that are associated with the criterion, regardless of the item content. The MMPI is an example of a scale that was developed using the external approach. For the MMPI, the criterion was a group (i.e., a criterion group approach), or more accurately, multiple groups: patients with different disorders and controls. The original MMPI was not developed based on theory (e.g., theoretical understanding of the construct of depression); instead, it was developed based on items’ empirical associations with a criterion group. Because an external approach relies on an external criterion, if people lose interest in the scale criterion, the scale loses interest.
Consider the development of the MMPI as an example of a measure that was developed using the external approach to scale construction. The developers grouped people together based on their criterion status, for example one group of people with schizophrenia and a control group that does not have mental disorders. How did they develop the test? The idea of the external approach is to let nature decide what goes into the test. So, the MMPI developers sampled thousands of questions very broadly from pre-existing questionnaires of personality, symptoms, etc. Then, they had the criterion groups (e.g., schizophrenia) and control groups answer the questions. They examined the item responses to determine which items discriminate between groups (i.e., which items are associated with criterion group status). And if an item(s) is good at discriminating between the criterion and control groups, the items are selected for the measure. It was purely empirical business—i.e., dustbowl empiricism. In sum, using an external approach, item selection depends on the discriminatory power of each item to inform about an external criterion of interest. Such an approach does not require having any theoretical assumptions about item functioning.
18.4.1.1 Pros
There are several pros of using the external approach to develop measures:
- You do not need to know anything—it requires no theory or theoretical knowledge about disorders and their etiology
- There is likely to be some generalizability of the utility of the measure in the future because there is some carryover of criterion-related validity
- The measure has some practical utility given its relation to criteria of interest
- “Subtle items” with poor face validity can be selected solely based on their discriminatory power. Subtle items are items that neither you nor the respondent predicted would show differences between groups. Subtle items provide an advantage that the data are moving beyond our ignorance. It is also an advantage that clients cannot fake subtle items as well as they can more obvious items.
18.4.1.2 Cons
There are also cons of using the external approach to develop measures:
- Measures developed using the external approach have lower content validity and/or face validity because they include subtle items. For example, the original version of the MMPI had low content validity and face validity. Using the external approach, it is possible to construct a scale that makes no sense due to lack of consideration of face validity.
- The success of the external approach depends highly on the quality of the criterion and control groups—if a criterion falls out of favor as an indicator of the construct (or interest fades), then the utility of the test decreases because it is no longer applicable.
- Items will not always generalize because the generalizability depends on the representativeness of the sample and the quality of the groups—if you select poor groups, it is not a representative sample, which results in a biased measure.
The validity of the scale depends on the representativeness of your groups in regard to the criterion of interest.
It is possible that your findings might not be generalizable if your sample is not—this is especially problematic when you rely only on data and not on theory.
- An example of the importance of the representativeness of the sample comes from the original MMPI. The norms of the original MMPI were based on largely White participants from Scandinavian, German, and Irish descent in the Midwestern U.S., with an average of an 8th grade education. The norms became known as “Minnesota farmers”. Therefore, “Minnesota normals” (i.e., the control group) were pretty “dull” normals. In addition, to be included in the norms, the respondents for the MMPI had to be waiting in the hospital (not everyone does that for family in the hospital) and had to be kind enough to take a 4–5 hour measure for psychologists (not all would do this). For all of these reasons, there were issues with poor generalizability of the original MMPI norms in the broader population. A scale is most likely to be valid when it is used with similar populations and in similar conditions.
- Shrinkage often occurs when using a measure developed using an external approach. As described in Section 10.4, shrinkage is when variables with stronger predictive power in the original data set tend to show somewhat smaller predictive power (smaller validity coefficients) when applied to new groups. When variables are selected empirically, they tend to show less predictive power (smaller validity coefficients) when applied to new groups during cross-validation. Shrinkage reflects a model over-fitting, because it is somewhat capitalizing on chance in selecting items. Many subtle items may be instances of Type I error (false positives). Shrinkage is especially likely when the original sample is small and/or unrepresentative and the number of variables considered for inclusion is large.
- Externally developed measures also have a problem of communicability (Burisch, 1984). For something to have meaning to others, it should have connection to constructs, which may not be true for many measures developed using the external approach.
- It can take a long time to develop measures using the external approach, and they tend to be longer to administer because of having more items. For instance, there are 567 items in the MMPI-2.
18.4.1.3 MMPI Examples
Paul Meehl wrote his dissertation to develop the K scale of the MMPI to attempt to detect faking good. In the context of the MMPI, faking good would involve under-reporting of symptoms. He developed the K scale based on all positive qualities that around half of people typically endorse. So, it is not obvious that the items reflect faking good, and if someone is trying to respond in a socially desirable way, they endorse more of these positive qualities. There is also a “faking bad” version of the scale, too. The “faking bad” (F) scale was developed as an attempt to detect malingering (over-reporting of symptoms).
However, the MMPI could pathologize normality in some cases. Some psychotic patients may have been identified as “faking bad” because they actually have had a lot of odd experiences. And very healthy people may have gotten higher score on “faking good”, but they just may be very positive and well-adjusted. As examples from the original MMPI from 1940, male teenagers tended to have elevated scores on the psychopathy and mania scales. Graduate students, including female graduate students, tended to have higher “masculine” scores on the Masculinity/Femininity (Mf) scale. This shows that non-clinical samples can still have “clinical” scores. In the 1930s–1940s, there was an emphasis on developing empirically based measures, where the researchers rely on data, not theory as had previously been emphasized.
18.4.2 Deductive Approach to Scale Construction
The deductive approach to developing a personality measure is also called a rational, theoretical, or intuitive approach. Using a deductive approach, the choice and definition of constructs precede and govern the formulation of items. That is, when using a deductive approach, we deduce the items from a pre-existing theory or conceptual framework. Item pools are generated using theoretical considerations, and item selection depends on possessing a rich theoretical knowledge about the construct and selecting which items assess the construct the best. In a deductive approach, the measure developer deduces the content; they do not rely on criterion data to select the content. Deducing the content involves thinking and talking about the construct, and having experts write items that they think would do well in eliciting information about the construct. The measure developer deduces from the construct which items to use. Therefore, the deductive approach completely depends on our ability to understand a given construct and translate this understanding to the generation of item content that will be understood by the examinees in such a way that it elicits accurate ratings for the construct of interest. Most assessments are developed using the deductive approach.
18.4.2.1 Pros
There are several pros of using the deductive approach to develop measures:
- Using the deductive approach is fast, easy, and short. Generating such scales requires few people, and is often fast and accurate. It does not typically take as much time to develop a measure using the deductive approach. Moreover, it allows the possibility of short scales that are quick to administer. By contrast to short scales developed by the deductive approach, the MMPI (developed using the external approach) is very long.
- Measures developed (well) using the deductive approach are always content valid because of the reliance on theory—items tend to be prototypical of the construct.
- Measures developed using the deductive approach are usually face valid, more likely than external approach. Face validity is often an advantage, but not always. Face validity can help with disseminability because others may be more likely to adopt it if it appears to assess what it claims to assess. However, face validity is not desirable when trying to prevent faking good or faking bad.
- Measures developed using the deductive approach tend to have better communicability—i.e., how comprehensible the information communicated is to the examiner based on the responses.
18.4.2.2 Cons
There are also cons of using the deductive approach to develop measures:
- If your theory or understanding is wrong, your scale will be wrong!
- Additionally, if the construct itself is vague, and there is overlap between constructs, scales may be difficult to differentiate between them, making it difficult to establish discriminant validity. Many theories and constructs overlap. Therefore, measures often overlap—even measures with very different names! For example, consider the Rosenberg Self-Esteem Scale and the Spielberger State–Trait Anxiety Inventory:
Items on the Rosenberg Self-Esteem Scale include:
- “At times I think I am no good at all”
- “I certainly feel useless at times”
- “On the whole, I am satisfied with myself”
Items on the Spielberger State–Trait Anxiety Inventory (STAI):
- “I lack self-confidence”
- “I feel inadequate”
- “I feel satisfied with myself”
18.4.3 Inductive Approach to Scale Construction
The inductive approach to developing a personality measure is also called an internal or item-metric approach. The inductive approach is an empirical, data-driven approach for scale construction, in which scales are derived from the pre-existing internal associations between items. That is, when using an inductive approach, we induce the construct(s) from the pattern of associations (and non-associations) among the items. A large pool of items is selected, and scales are generated from the item pools based on the structure of the internal association between items. The inductive approach assumes that universal laws exist for personality structure, that is, that there is a natural structure. The hope is that personality has simple structure: that each item loads onto (i.e., reflects) one and only one factor. It is the hope of the inductive approach that there is simple structure because it makes the natural structure easier to detect using available methods.
The inductive approach is empirical because the answers come from within the data. But the inductive approach differs from the external approach. In the inductive approach, the data come from the internal structure of the measure’s items. The empirical approach is also based on empirical data. Science involves prediction and both the inductive and empirical approach use prediction. The empirical approach examines how items predict some external criterion. By contrast, the inductive approach examines how items predict or relate to each other. The goal of the inductive approach is to “describe nature at its joints”.
According to the inductive approach, once you understand constructs, you can understand how they are connected to each other. The external approach does not really care about the items themselves. In the inductive approach, you need to use theoretical knowledge to interpret findings. The deductive approach uses theory up front to make the scale. The inductive approach concerns itself with the items and what inferences can be made. The method helps group the large set of items into subscales based on clusters of items that covary most strongly with each other using factor analysis, and it drops items with a low item–total correlation, factor loading, or discrimination parameter.
Factor analysis is used for the inductive approach to developing measures. It is used to evaluate the internal structure of a measure, and ideally, the structure of a construct. Factor analysis is considered to be a “pure” data-driven method for structuring data, but as noted in Section 14.1.4, the “truth” that we get depends heavily on the decisions we make regarding the parameters of our factor analysis. In sum, factor analysis is not purely inductive because the result is influenced by many decisions by the investigator. Even though the inductive approach (factor analysis) is empirical, theory and interpretability should also inform decisions.
18.4.3.1 Pros
There are several pros of using the inductive approach to develop measures:
- The inductive approach yields estimates of associations between items and can arrive at estimates of a simple, homogeneous construct.
- You do not need to know much to use the inductive approach (relative to the deductive approach): just use the items you have and use a data reduction approach.
- The inductive approach can derive short, homogeneous scales. Then, you can see how constructs relate to other constructs.
- The inductive approach is a “purer” method of scale construction because it relies on the natural structure of the data, and no theoretical knowledge or validation to a criterion is required on the front end of scale development.
- The data are allowed to “speak for themselves”.
18.4.3.2 Cons
There are also cons of using the inductive approach to develop measures:
- The inductivists (i.e., users of the inductive approach) hope that a simple structure exists within a set of items and that this structure can meaningfully differentiate between constructs. If there is no simple structure, interpretations of scales that emerge can be difficult.
- In addition, this approach is not “pure” because the structure we get depends on the analysis decisions we make. The answers you get depend on the decisions you make, and there really is no basis on which to make decisions. This is called indeterminacy. There are a number of decisions in factor analysis, including decisions such as the number of factors and the nature of factors—i.e., how to interpret them.
- Factor analysis is not straightforward, and depends on decisions made along the way. Therefore, some argue because so much is in the hands of the investigator that factor analysis is really a semi-empirical approach.
- SPSS likely contributes to the problem because it makes so many decisions for you, and many have no idea what they are doing! SPSS is for ease of use, but it is limiting. In SPSS, you can use principal component analysis (PCA) for item extraction. Investigators often determine how many components/factors to keep based on the criterion of keeping components with eigenvalues greater than 1, often use orthogonal rotation of data, etc. Factor analysis and PCA are described in Chapter 14.
18.4.4 Hybrid Approach
The preceding discussion described the three primary approaches to developing objective personality measures. However, the approaches can be mixed. For instance, one could write a large set of items based on theory (i.e., the deductive approach) and then pick items to keep based on their criterion-related validity (i.e., the external approach), and group them into scales based on their internal structure (i.e., the inductive approach). There is not strong evidence for the superiority of any of the approaches compared to the others.
18.5 Measure Development and Item Selection
Despite not having strong evidence for the superiority of any of the approaches to scale construction, best practices to measure development include:
- Start with theory to define the construct and create item pools, using a deductive approach.
- Be inclusive at this stage. Create more items than you will actually use—even if items are only tangentially related—so you have a broad pool of items.
- Include items of other constructs to establish the boundaries of the construct, i.e., discriminant validity.
- Then, test these item pools, and consider their empirical relations to revise and/or drop items.
Ideally, you would test the items in large and heterogeneous samples that are representative of the population.
- Examine the items in relation to external criteria, using an empirical approach.
- Examine items in relation to each other, using an inductive approach.
This likely involves factor analysis and/or item response theory.
- We want items, collectively, to span the full range of difficulty/severity of the construct in the target range of interest. It is important for the items to have accuracy (i.e., strong discrimination and information) in the target range of interest on the construct (e.g., low, medium, and/or high). The target range of interest depends on the purpose of the assessment, as described in Section 8.1.7.1. For example, items used for diagnosis should focus on higher levels of the construct, whereas items used for screening should identify those with elevated risk but might not need to discriminate at higher levels. For assessing individual differences, you would want items that discriminate across the full range, including at the lower end.
- Items should show some internal consistency, as evidenced by an inter-item or item–total correlation, but items should not be too highly inter-correlated. If items are too highly correlated, then they are redundant and do not provide unique information. Inter-item correlations should only be moderate, e.g., should range from approximately .15 to .50. But items should be highly correlated with the latent factor representing the target construct. That is, the items should have a high discrimination or a strong factor loading.
- Then, interpret the results and label the factors based on theory.
- Evaluate multiple aspects of reliability and validity of the scale.
Other ideas in scale development are discussed by Burisch (1984), L. A. Clark & Watson (1995), L. A. Clark & Watson (2019), and Loevinger (1957).
18.5.1 The Response Scale
Evidence suggests that there may not benefits of having more than six response options for likert-scale items that assess personality (Simms et al., 2019).
18.6 Emerging Techniques
One emerging technique for developing personalized models of personality is the group iterative multiple model estimation (GIMME) model (Wright et al., 2019), as described in Section 23.5.5.
18.7 The Flawed Nature of Self-Assessments
It is a common finding that people tend to over-estimate their skill and abilities—most people tend to describe themselves as “above average”, which is statistically impossible. People are over-confident, and they over-estimate the likelihood of achieving desirable outcomes and underestimate how long it will take to complete future projects. Self-report is only weakly associated with people’s actual behavior.
There are there prominent ways in which self-assessment has been shown to be flawed:
- response bias
- ambiguity of items
- lack of insight by people to rate themselves
18.7.1 Response Bias
One way that self-assessment has been shown to be flawed is in terms of response bias. Bias involves a systematic measurement error. For instance, it is not uncommon for participants to fake good or fake bad on assessments due to situational reasons or due to how questions are worded. When answering questions, many people desire to seem better than they are. This phenomenon is called social desirability bias, which is a form of method bias in which people systematically adjust their responses to reflect more socially desirable attributes. The degree of a person’s faking has been shown to be related to social desirability bias (Bensch et al., 2019). If you want to want to know the true prevalence of a given behavior, you can deal with social desirability bias using a randomized response model, as described in Section 4.10.3.1. There are indicators of response bias that are worth considering (Burchett & Ben-Porath, 2019).
18.7.2 Ambiguity of Items
Another way that self-assessment has been shown to be flawed is in the ambiguity of items. People tend to have a difficult time providing an accurate characterization of their skills on tasks that are poorly defined or ambiguous. For example, what does it mean to be a “warm” parent? Beyond this, even the language on self-assessments can be highly ambiguous. For example, how often is “rarely”? Such questions can systematically skew answers to self-assessments.
18.7.3 Lack of Insight by People to Rate Themselves
A third way that self-assessment has been shown to be flawed is due to respondents’ lack of insight into the required information to make good self-assessments. People often make poor judgments because they lack the required skills and information necessary to have insight into their actual performance, or they neglect it when it is available. The lack of insight into poor judgments can also be caused by errors of omission—in which they do not know that they have made a mistake because they do not know what the best alternative would have been. Also, people infrequently get feedback from others on the constructs we are attempting to assess—as a result, their self-views are not informed by objective feedback.
18.7.4 Ways to Improve Self-Assessment
Ways to improve self-assessment are described by Dunning et al. (2004):
- Use clear items that are behaviorally specific
- Use an expanded response format rather than a Likert format (X. Zhang & Savalei, 2024)
- Provide frequent, timely, objective, and individualized feedback
- Use self-testing, following some delay of time after studying the material
- Review one’s past performance
- Use peer assessment
- Target the motivational basis of the over-confidence
- Benchmark—compare one’s performance against others’ performance
- Introduce “desirable difficulties” to instruction, such as spreading training over several sessions and varying the circumstances of the training. These challenges can harm the speed that students learn but leaves them better able to retain what they learned and to transfer it to new situations in the future.
- To account for over-confidence, add in safety factors and buffer time. People tend to under-estimate how long it will take to complete a project, known as the planning fallacy (Kahneman, 2011). For instance, add 30%–50% extra time to all time-completion estimates for projects.
18.7.5 Satisficing (Versus Optimizing)
There have been new developments in gaining insight into the cognitive processes by which respondents generate answers to survey questions (Krosnick, 1999).
18.7.5.1 Optimizing
Optimizing involves a respondent responding optimally to a question—i.e., responding in an unbiased and thorough manner. There are four cognitive steps or stages that respondents must complete to answer a question optimally:
- They interpret the question
- They search their memory for relevant information
- They integrate all relevant information into a single judgment
- They use that judgment to select a response
The complexity of the cognitive processes one must engage in when giving an optimal answer requires a lot of cognitive effort. Giving such effort can happen for a variety of reasons: desire of self-expression, being altruistic, desire for gratification, etc. The extent to which such motivations inspire a person to engage in the cognitive requirements to respond to questions in an unbiased and thorough manner is referred to as optimization. Optimizing deals with how hard the person worked and how much they care about giving their best response.
18.7.5.2 Satisficing
If, for some reason, a person is not motivated to expend the cognitive effort required to make an optimal response, and instead settle for a satisfactory response, they are said to be satisficing. That is, they are expending less effort that prevents obtaining the optimal answer. There are two types of satisficing: weak satisficing and strong satisficing. In weak satisficing, respondents execute all four cognitive steps, they are just less diligent about doing so, and they settle on selecting a satisfactory answer rather than the optimal answer. Weak satisficing may lead to selecting earlier response options without careful evaluation of later response options, which is susceptible to confirmation bias. In strong satisficing, a respondent skips the retrieval and judgment steps, interprets the question superficially and selects an answer based on what they think will be a reasonable (or “satisfactory”) response. Their answer is not reflective of a person’s actual feelings about the construct of interest. Answers could also be selected arbitrarily.
There are several conditions when satisficing is most likely to occur:
- The greater the task difficulty
- The lower the respondent’s ability
- The lower the respondent’s motivation
- When “No opinion” responses are an option
In sum, to reduce the likelihood of satisficing, match the task to the participant’s ability, make sure they have motivation to respond correctly, and do not provide a “no opinion” response option.
18.8 Observational Assessments
Given the challenges with self- and informant-report of personality, it can also be worth considering observational assessments. For example, one observational approach to assessing personality involves a “thin-slice” approach, in which observers briefly assess people’s personality via observations across a range of situations or contexts (Tackett, Lang, et al., 2019). Observational ratings of personality can then be combined with self- and informant-rated personality in a multitrait-multimethod matrix (Tackett, Lang, et al., 2019).
18.9 Structure of Personality
The most well-supported structure of personality is the five-factor model of personality. The highest-order dimensions of the five-factor model are defined by the Big Five. The Big Five are known by the acronym OCEAN: Openness to experience (versus closed-mindedness), Contientiousness (versus disorganization), Extraversion (versus intraversion), Agreeableness (versus disagreeableness), and Neuroticism (versus emotional stability).
18.10 Personality Across the Lifespan
As described by Costa Jr. et al. (2019), individual differences (i.e., rank order) in personality are relatively stable from middle childhood to old age. On average, neuroticism tends to decline, and agreeableness and contientiousness tend to increase with age (Costa Jr. et al., 2019). It is unclear how extraversion and openness to new experiences change across the life span.
18.11 Conclusion
In an objective personality test, a stimulus is presented to a respondent, who makes a closed-ended response, such as True/False or Likert ratings. An example of an objective personality test is the Minnesota Multiphasic Personality Inventory (MMPI). There are three primary approaches to developing personality measures and other scales. One is the external approach, in which items are selected based on their association with an external criterion. A second approach is the deductive approach, in which items are deduced based on theory. A third approach is the inductive approach, in which items are selected based on the internal association between items that are intended to assess the same construct. Guidelines for measurement development are provided. Nevertheless, relying on self-report and self-assessment is prone to key weaknesses including response bias, ambiguity of items, lack of insight, and satisficing. There are ways to improve self-assessment, but it can also be helpful to supplement self-assessments with informants’ ratings and with observational assessments.