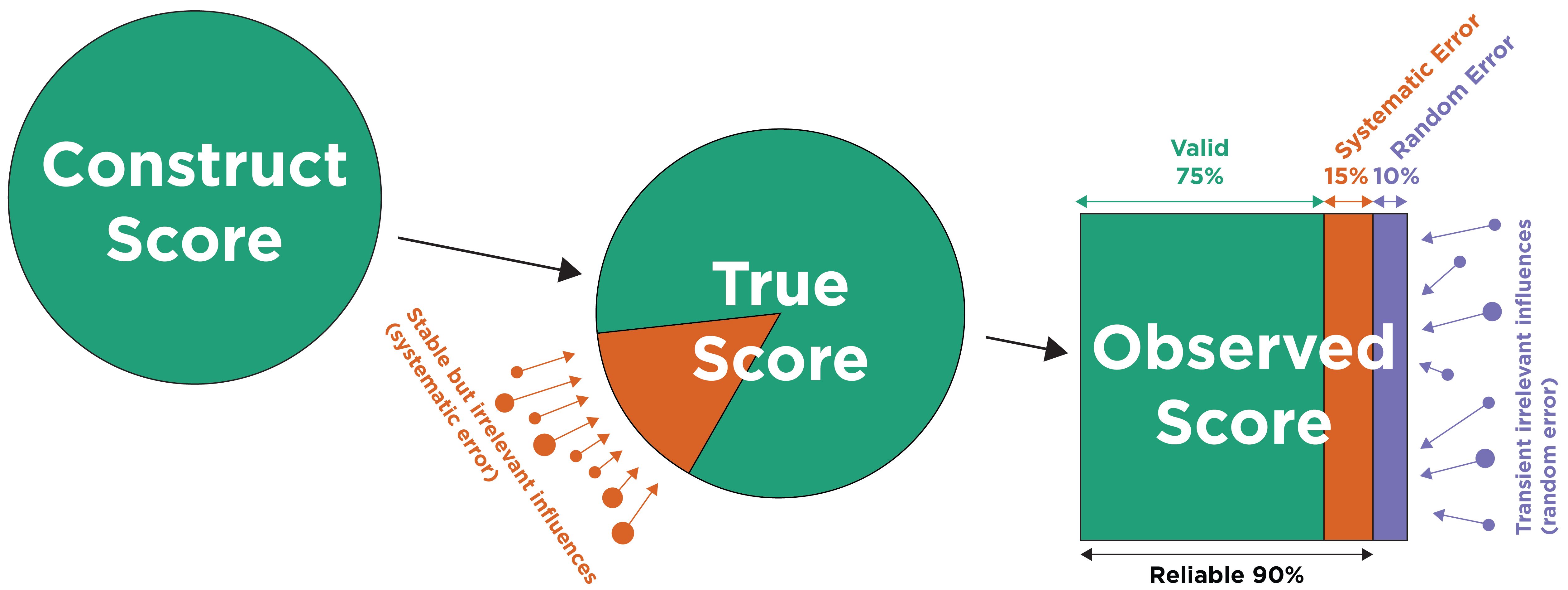
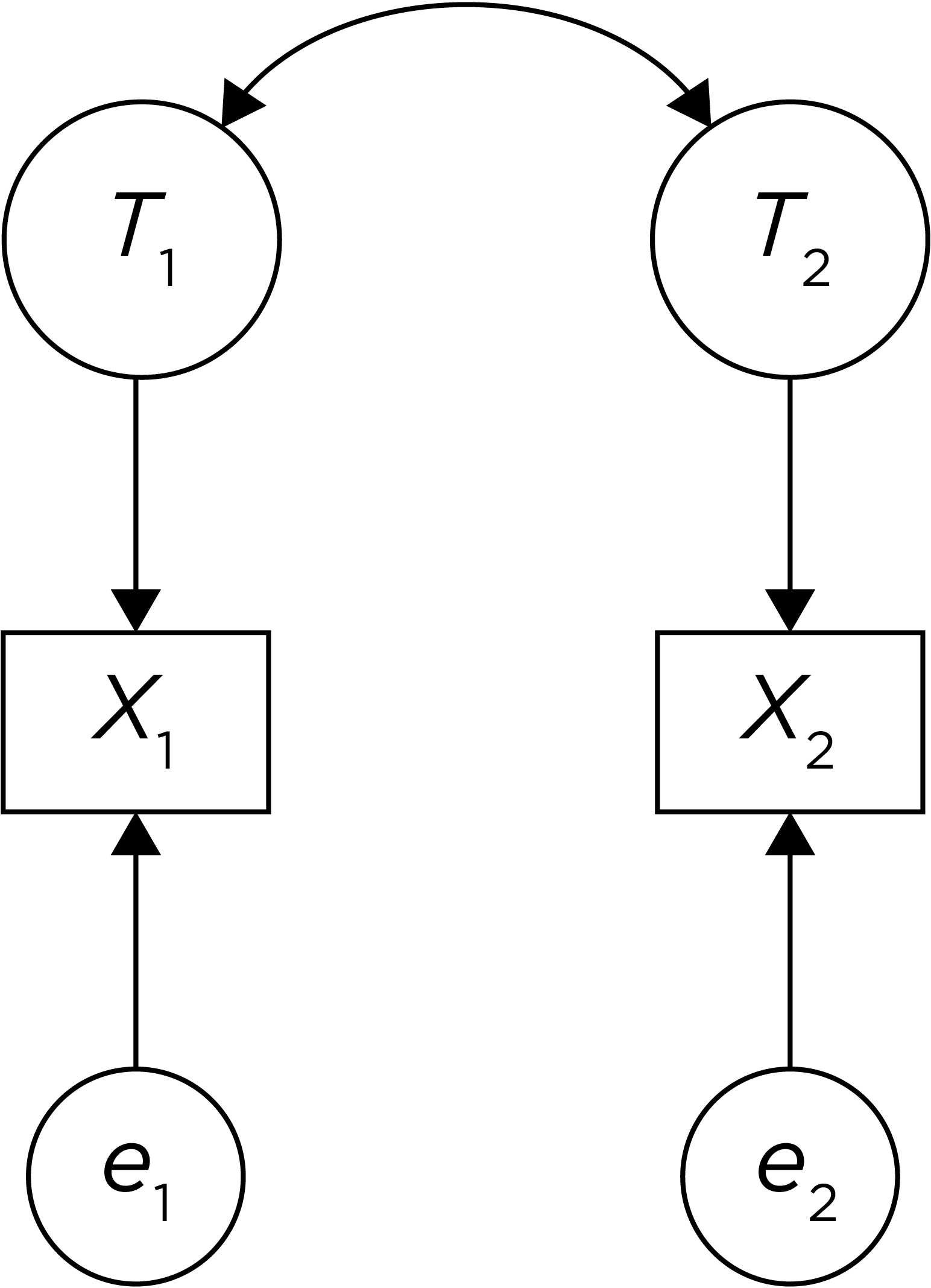
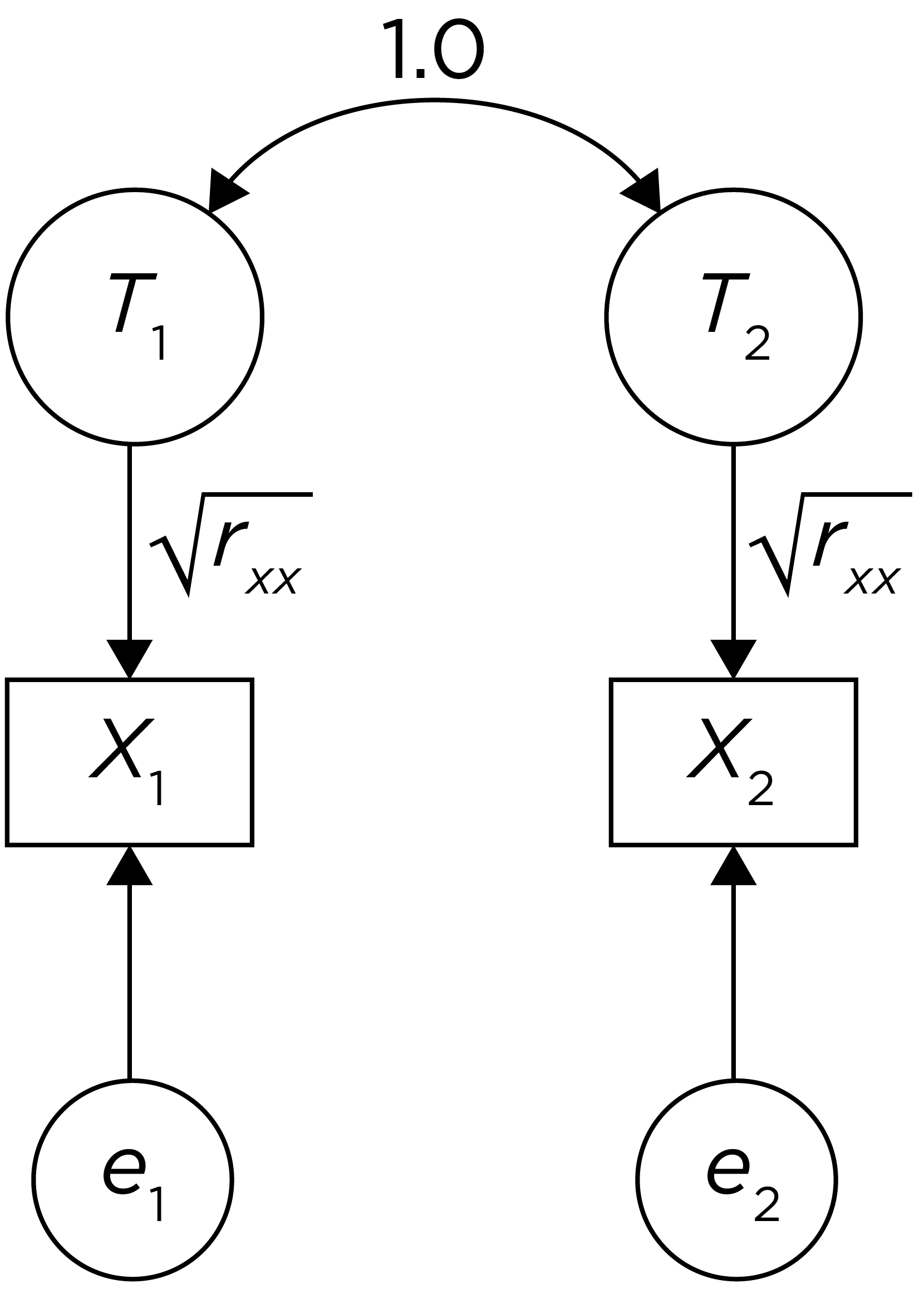
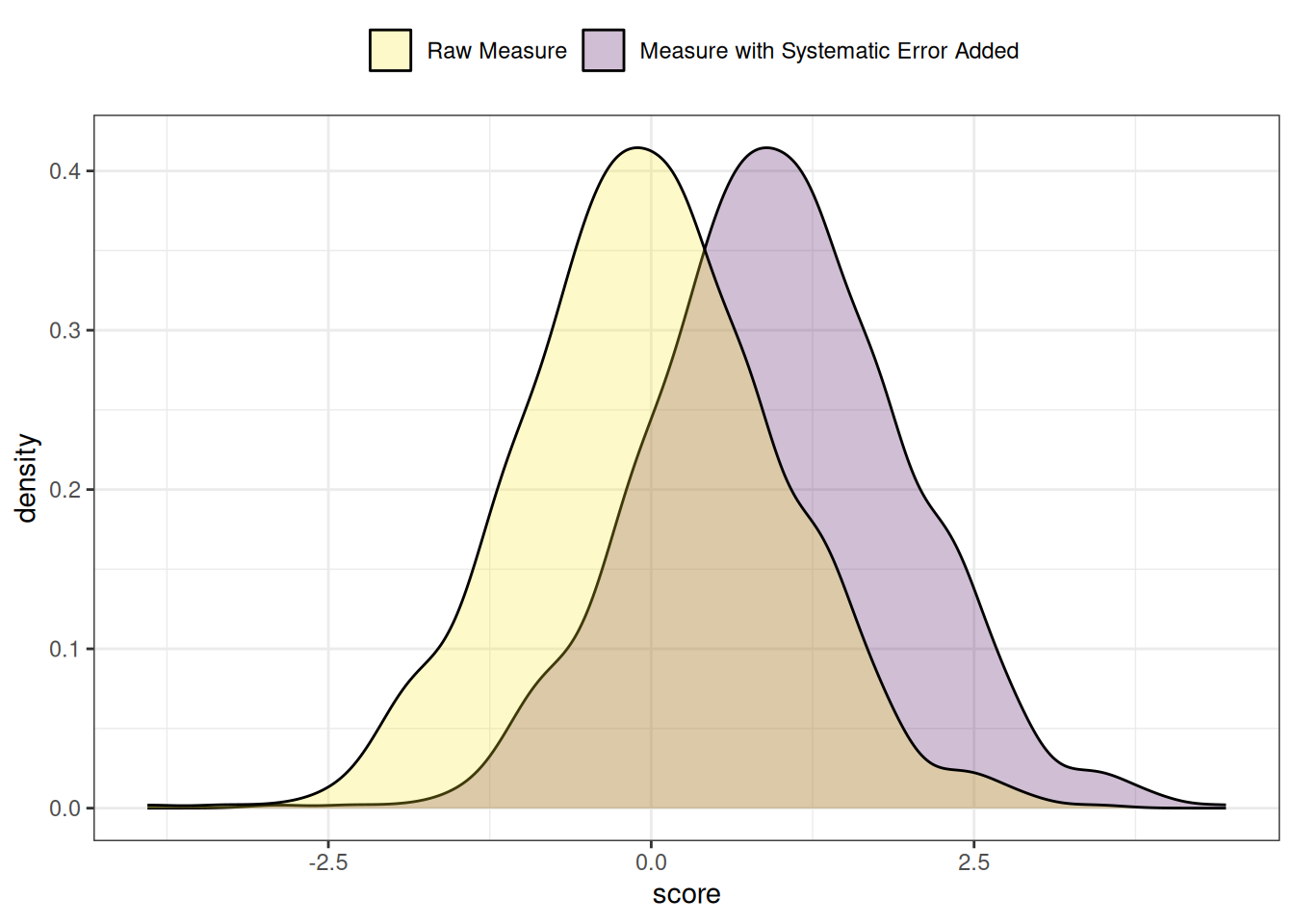
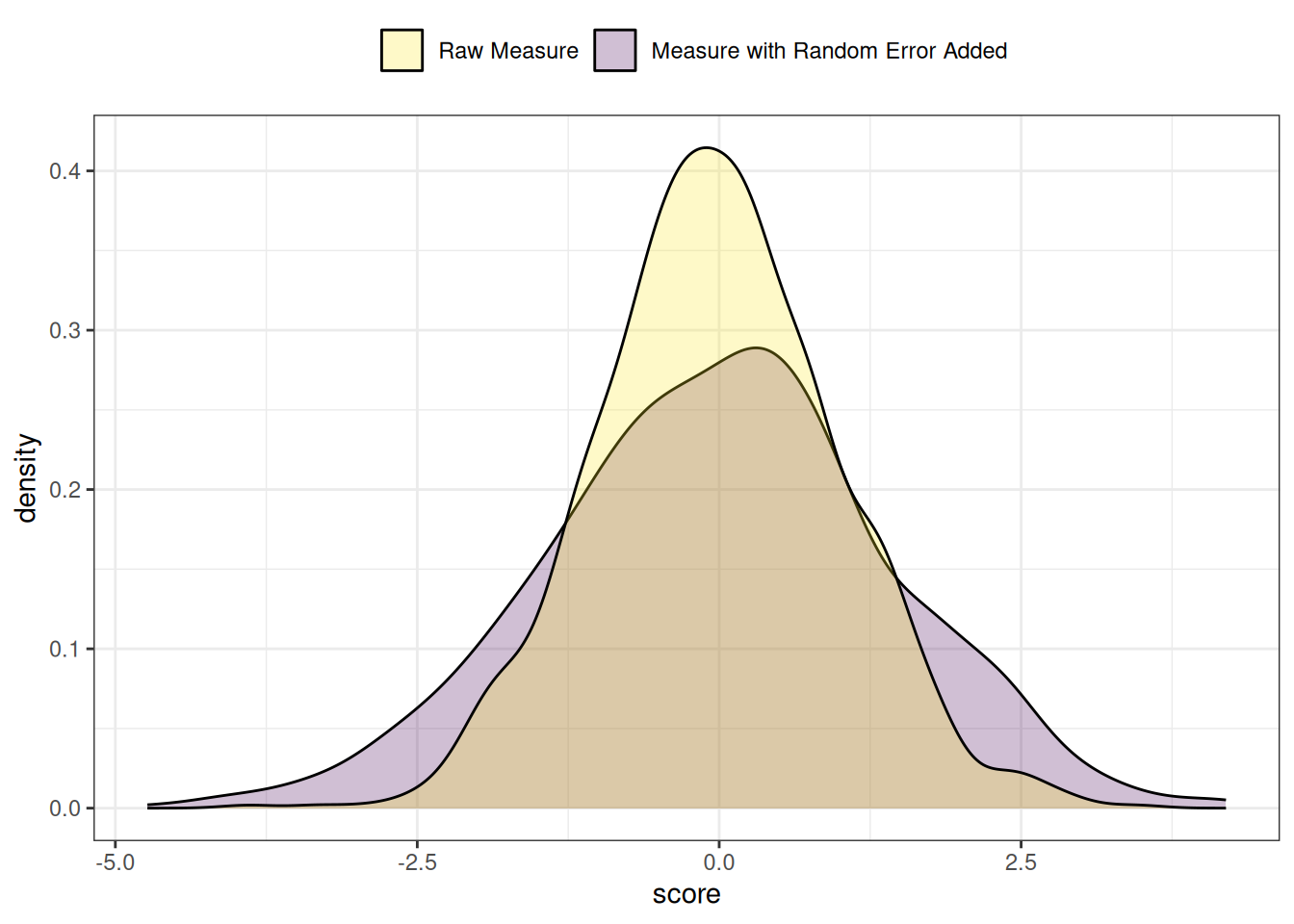
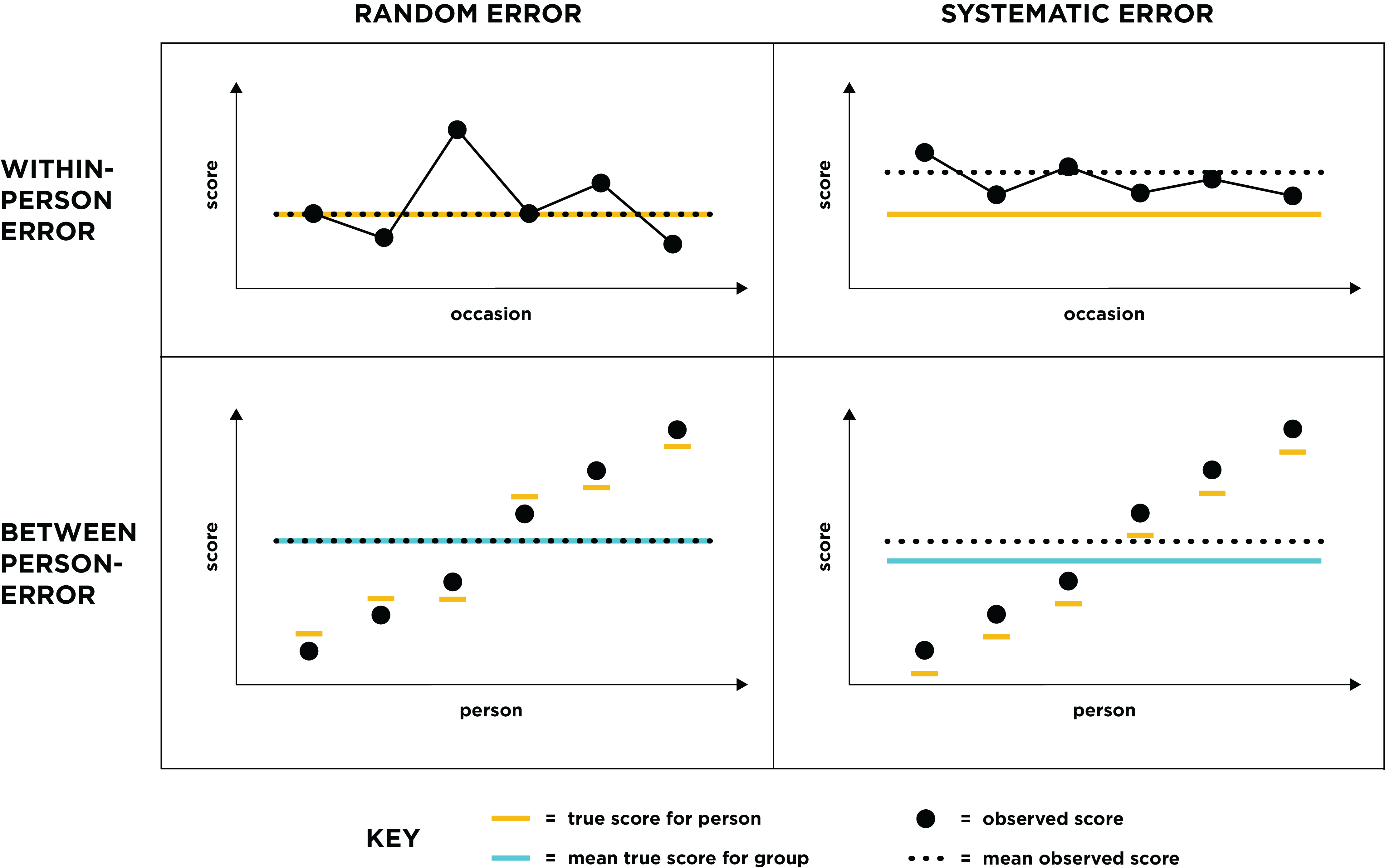
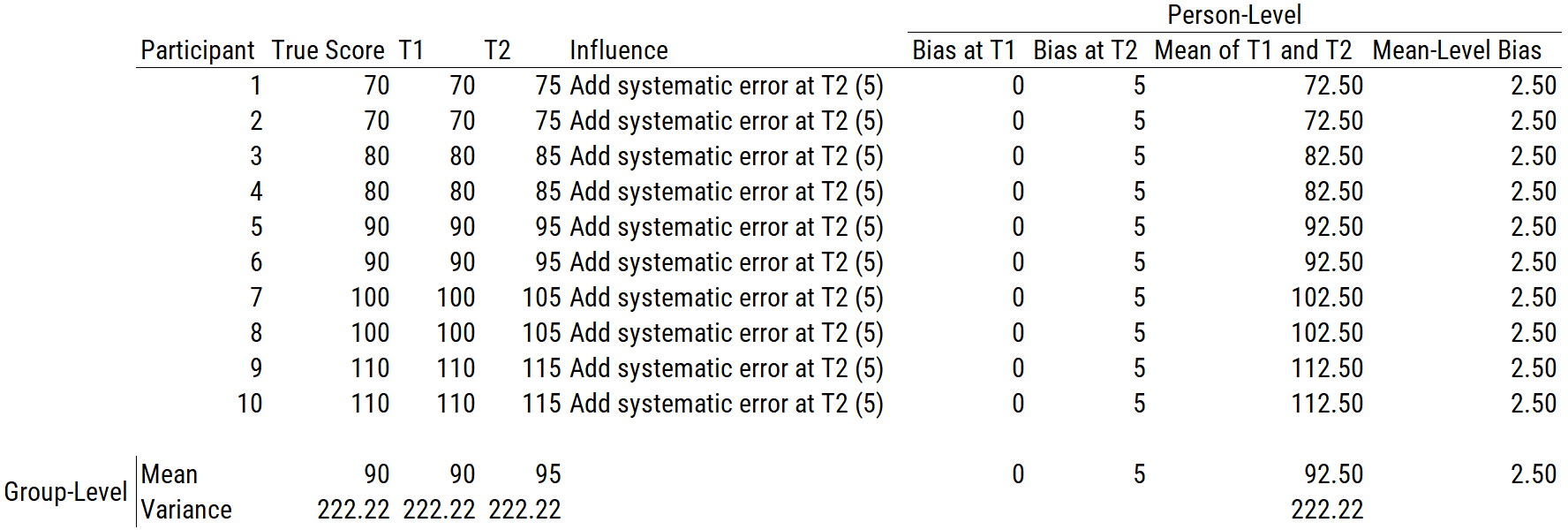
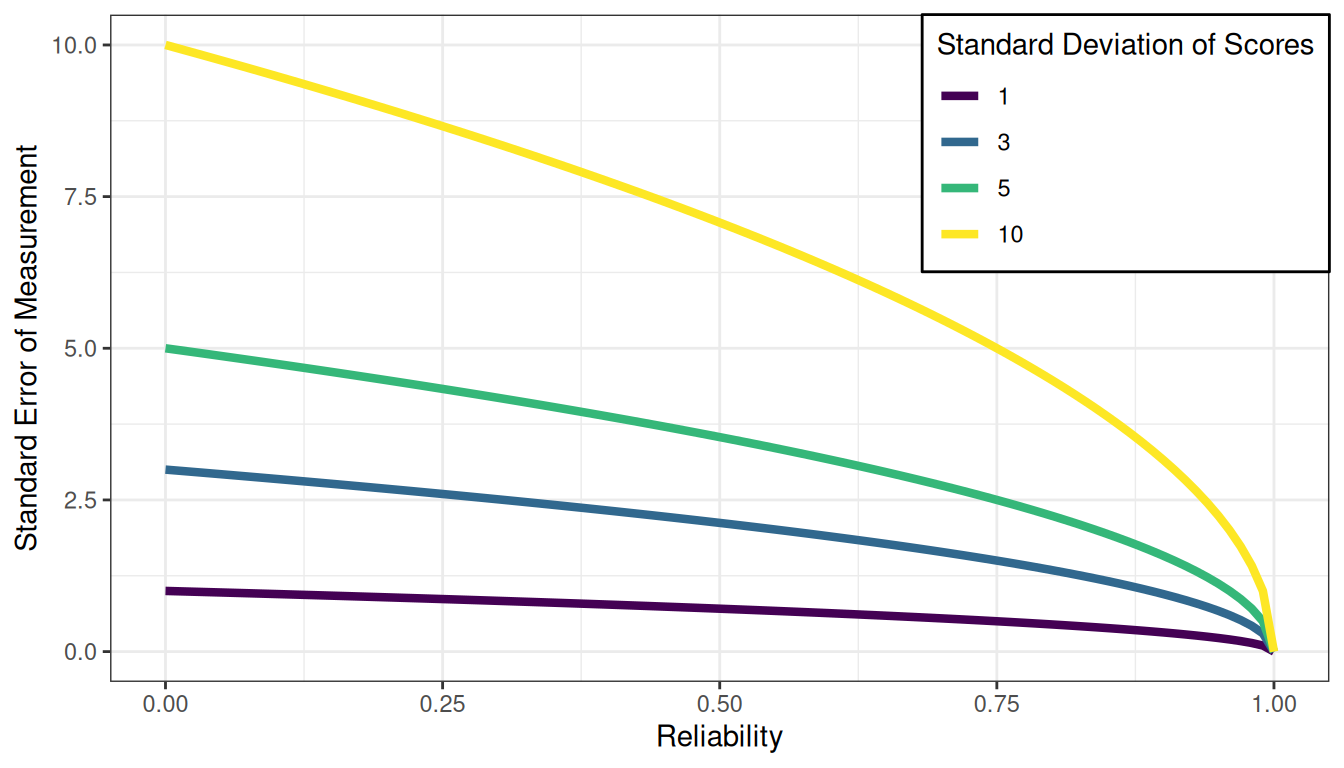
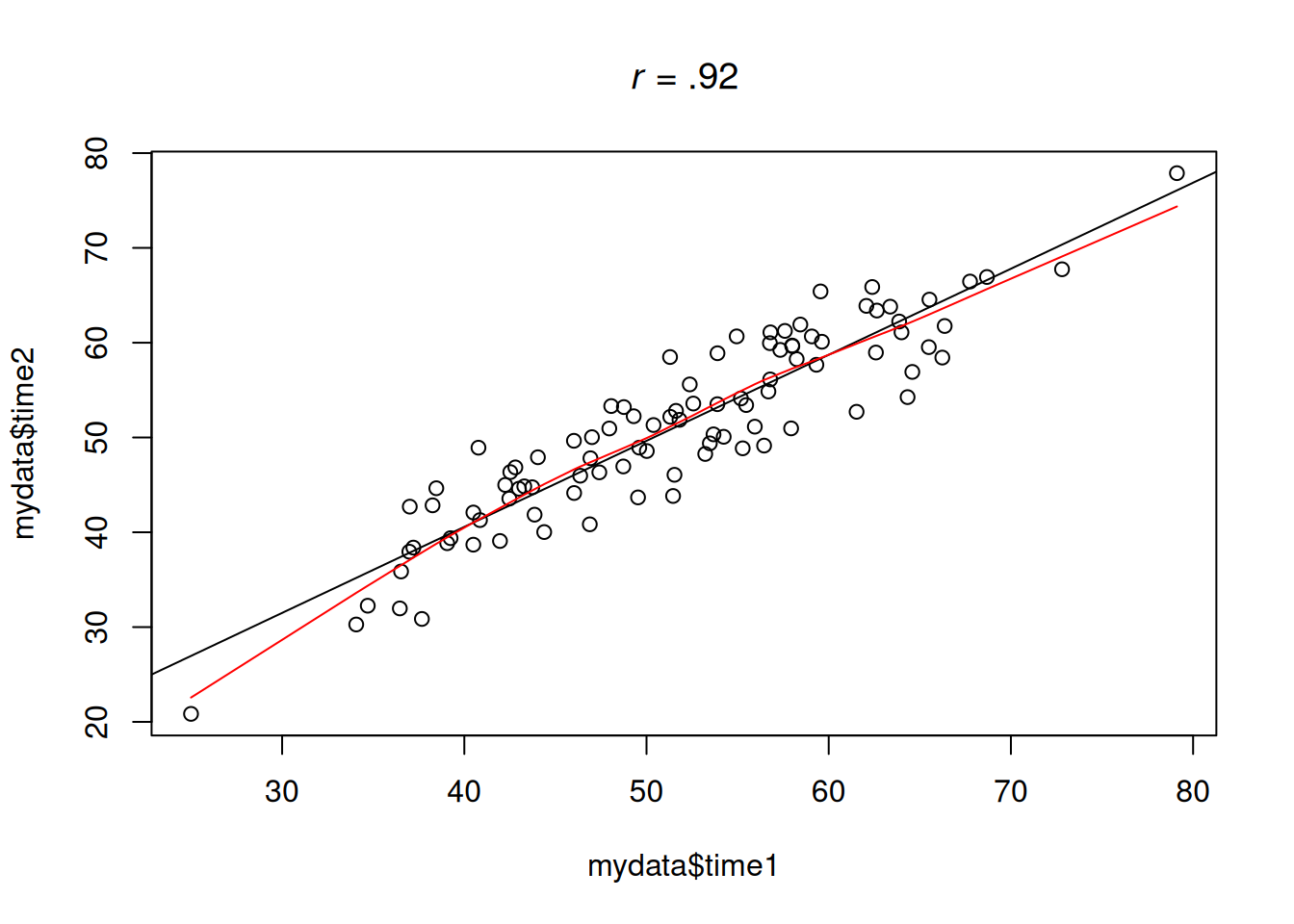
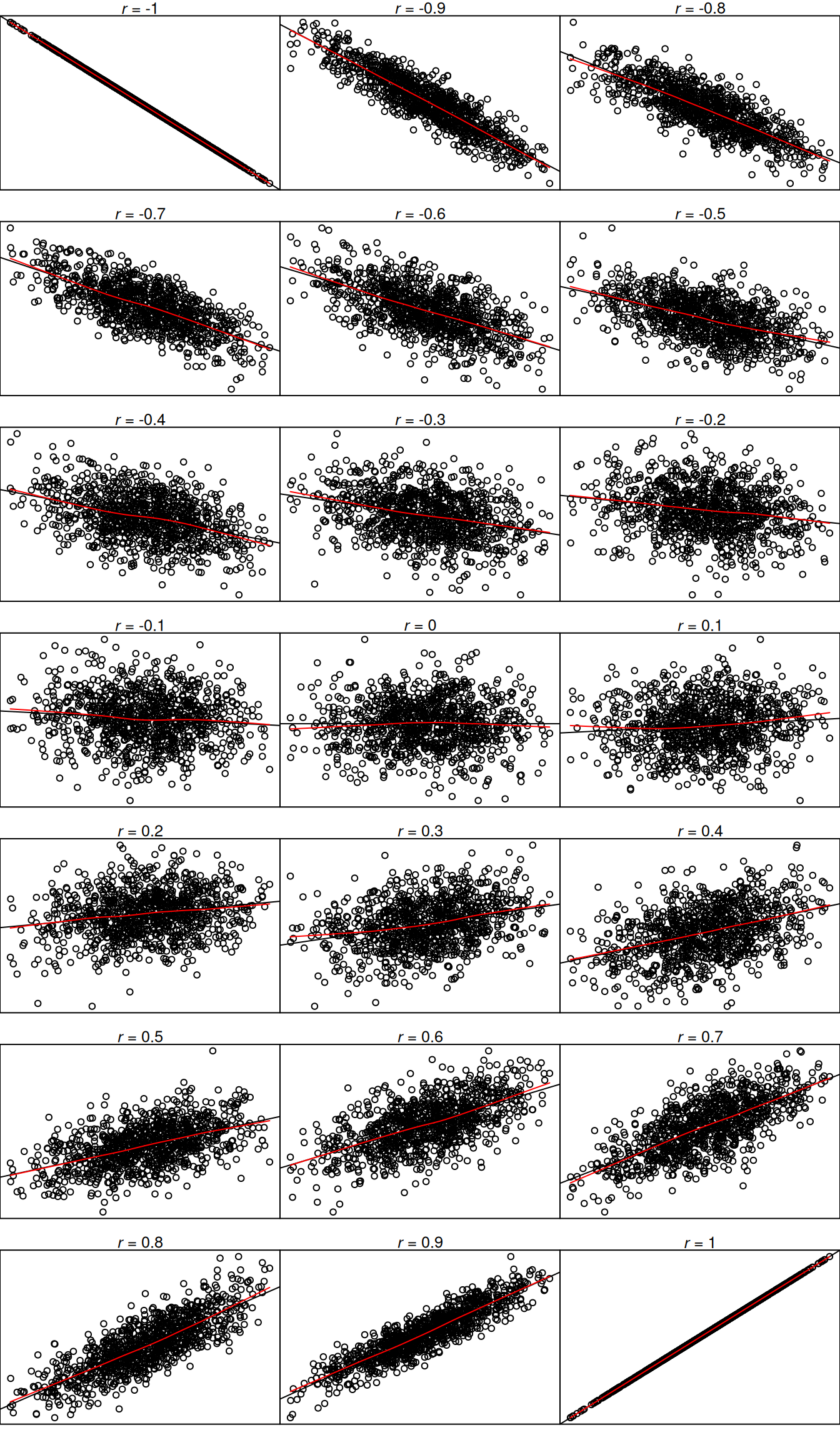
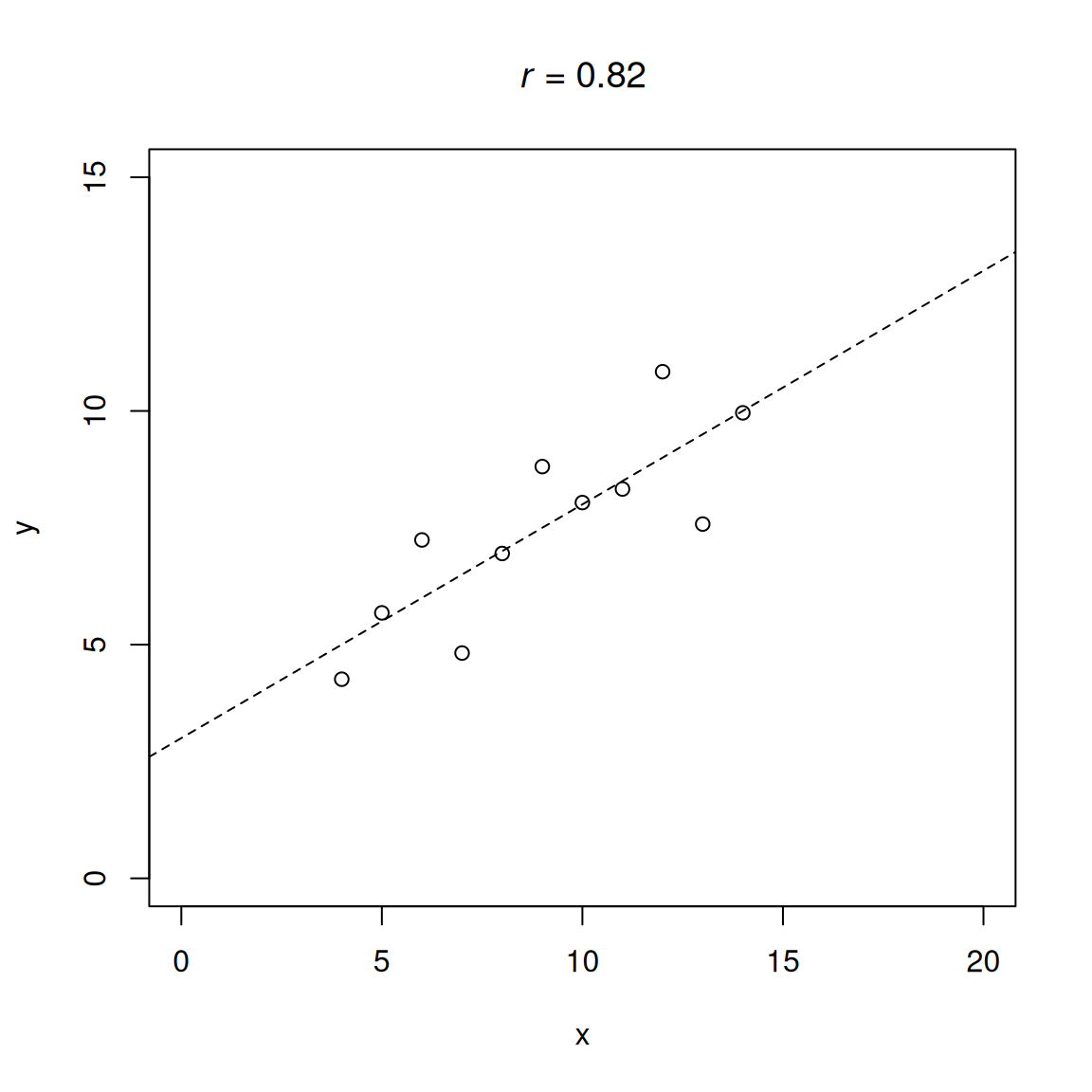
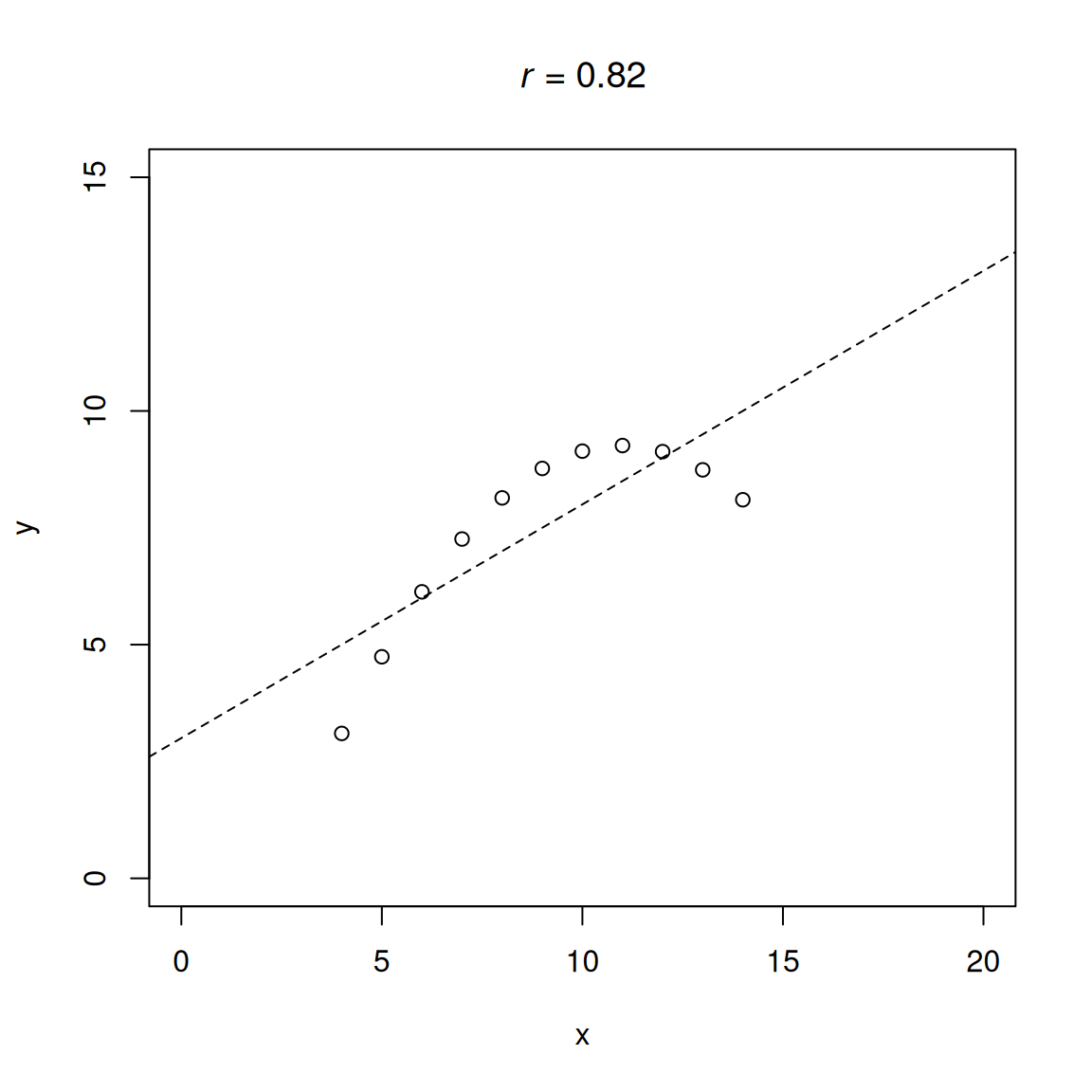
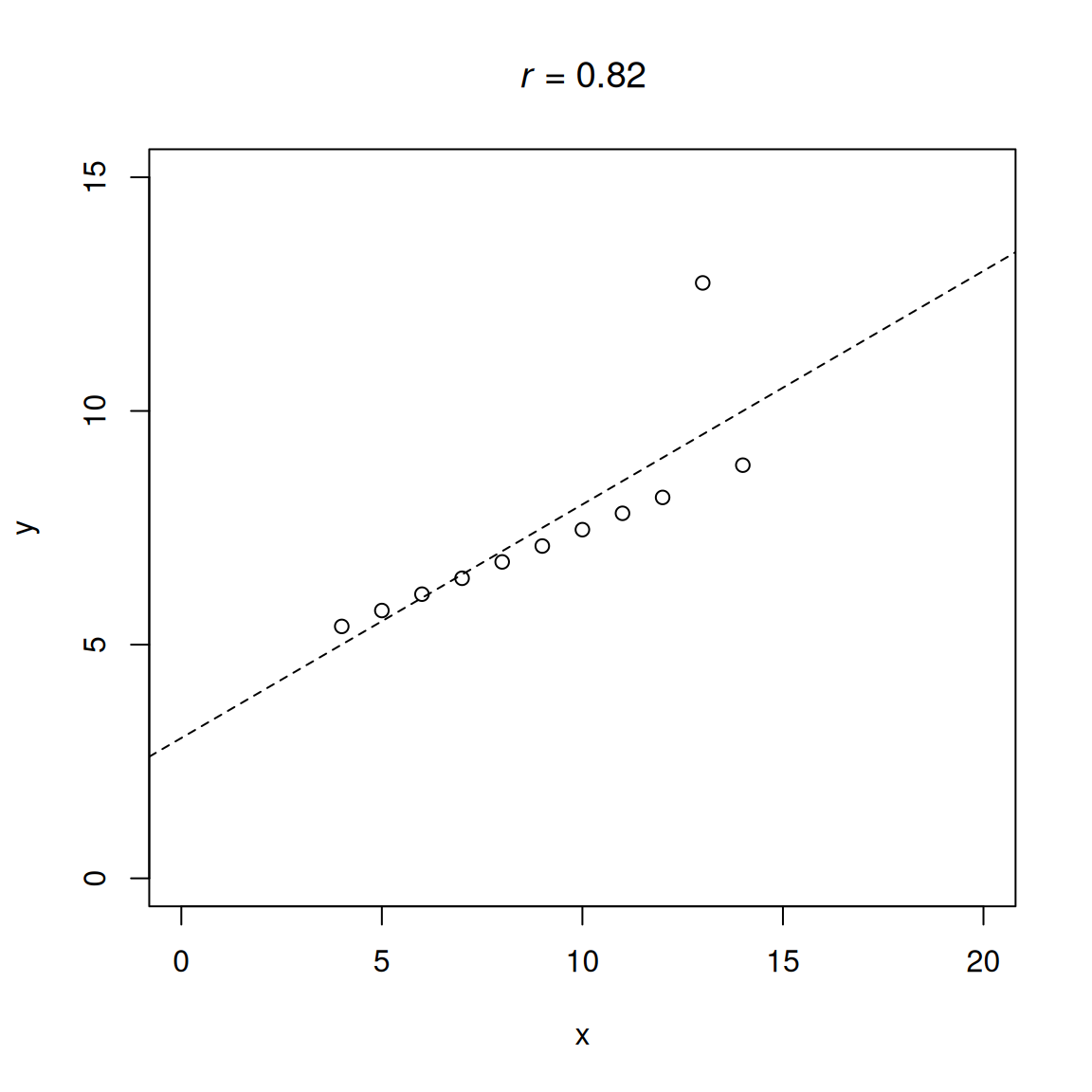
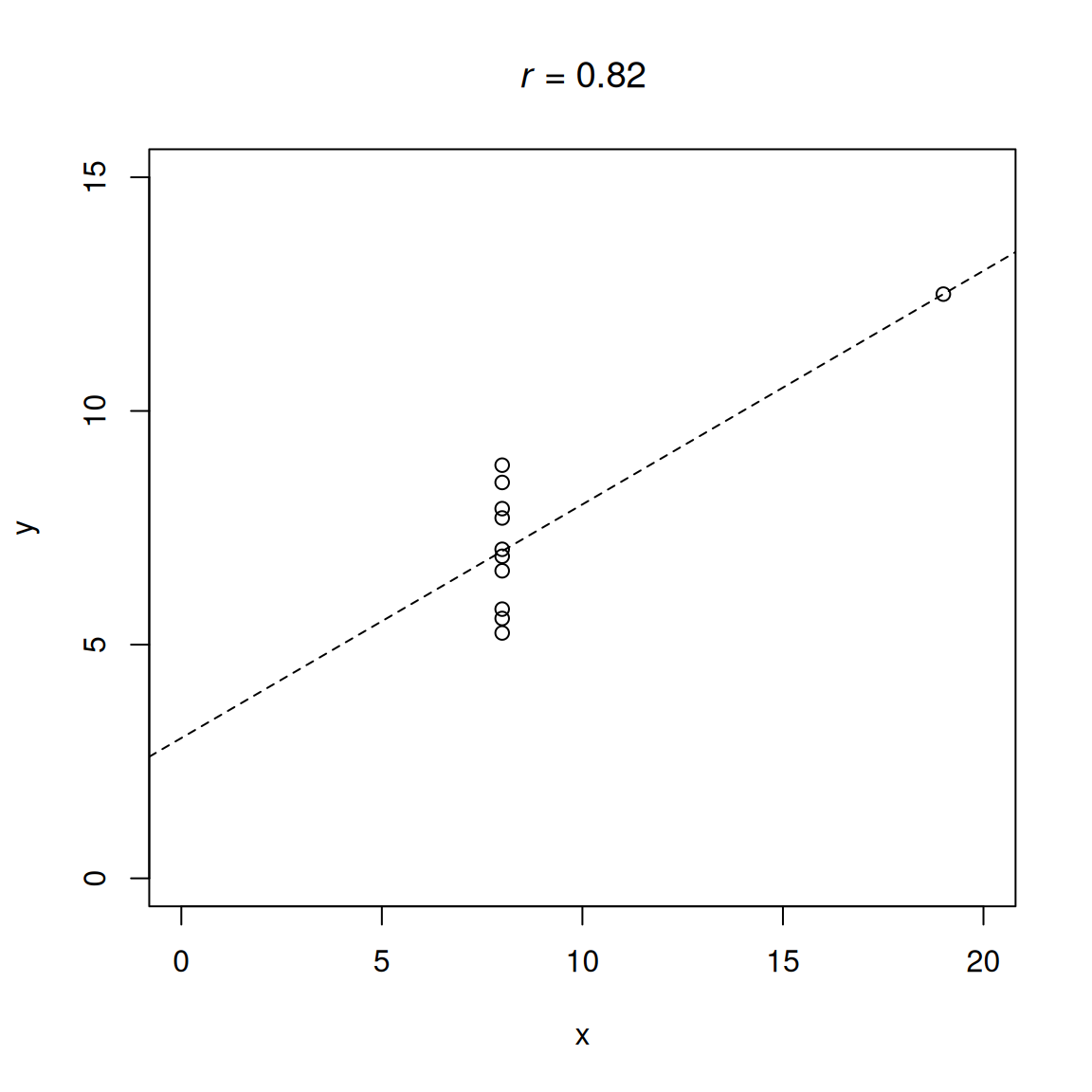
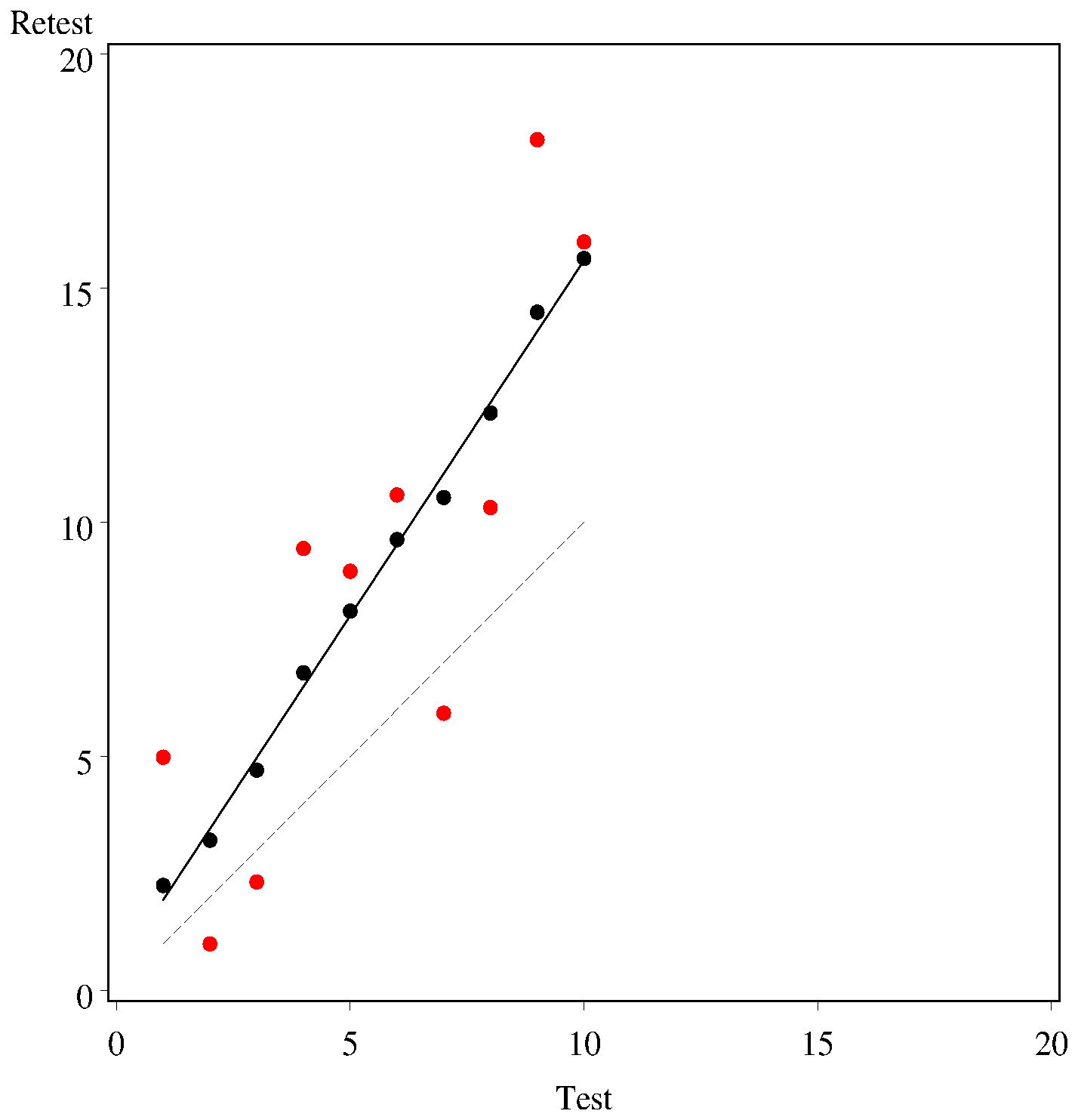
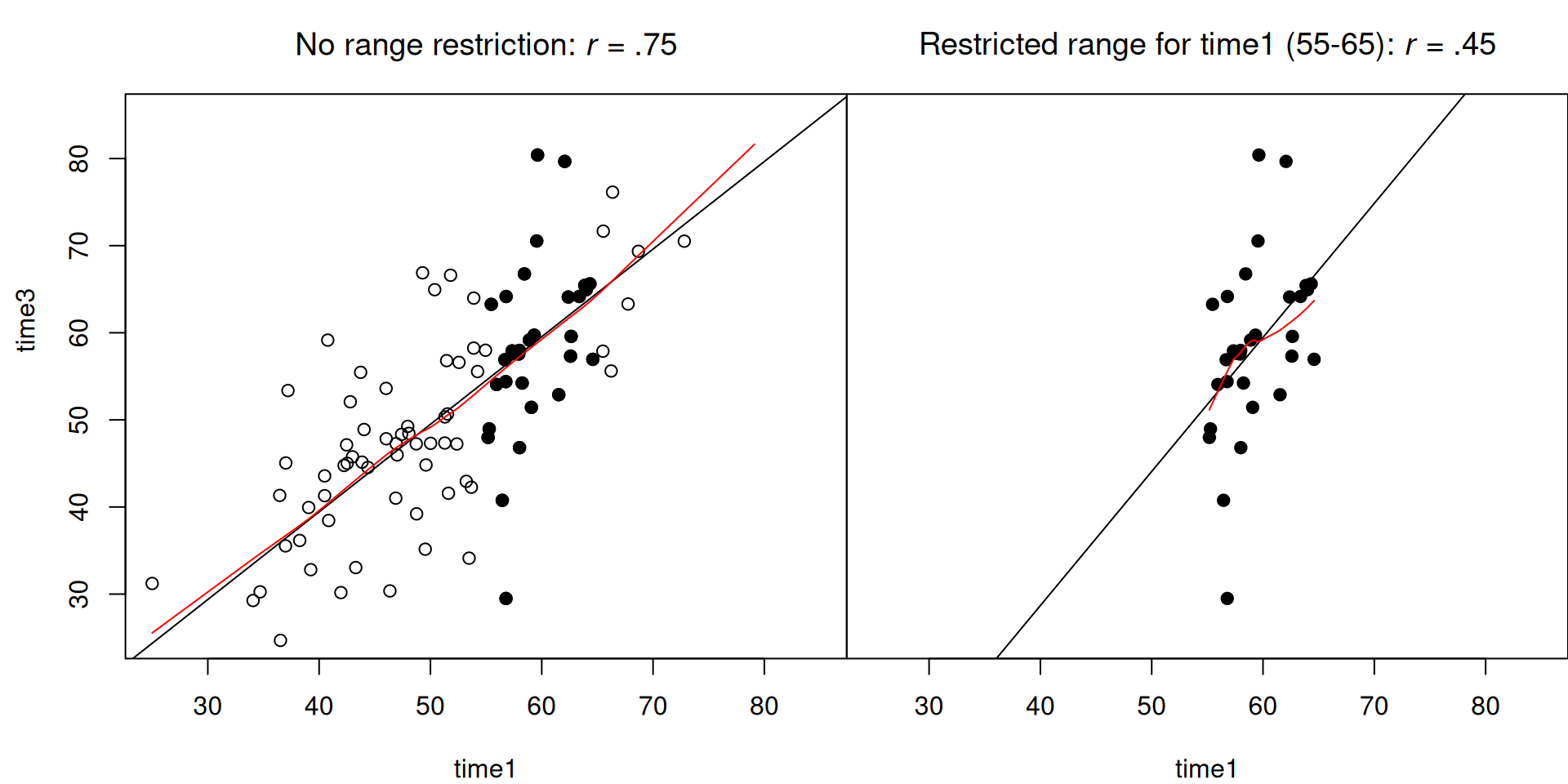
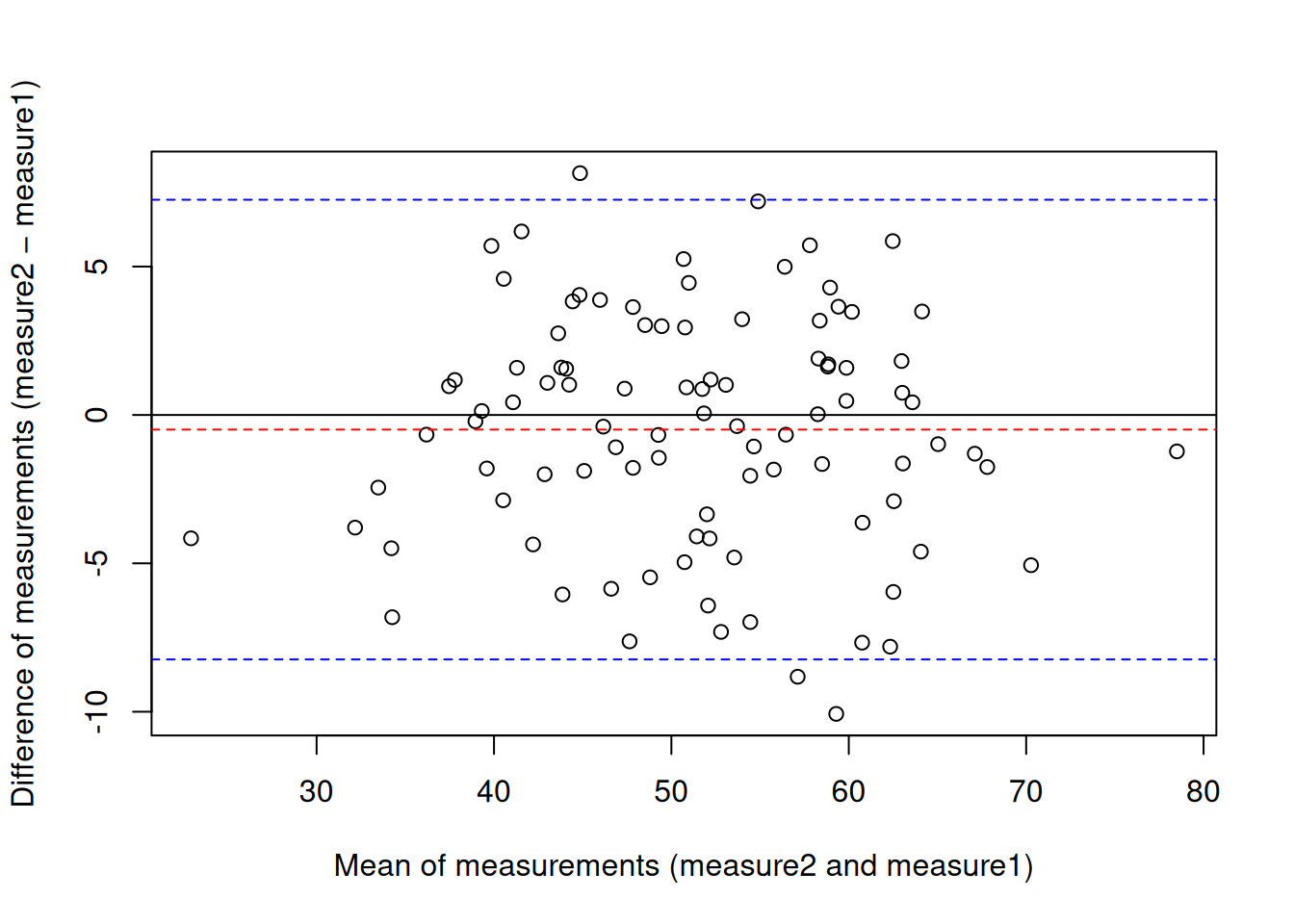
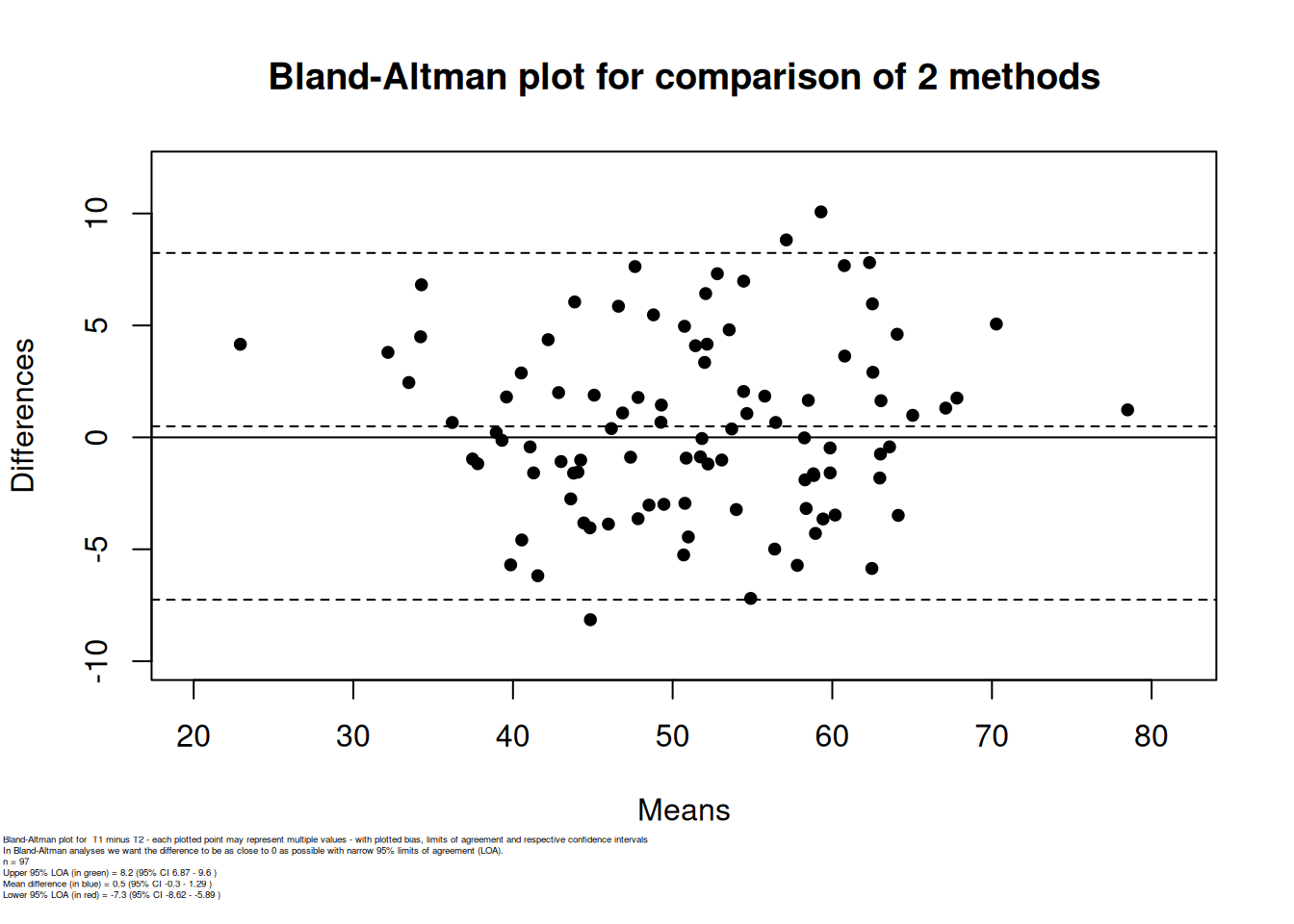
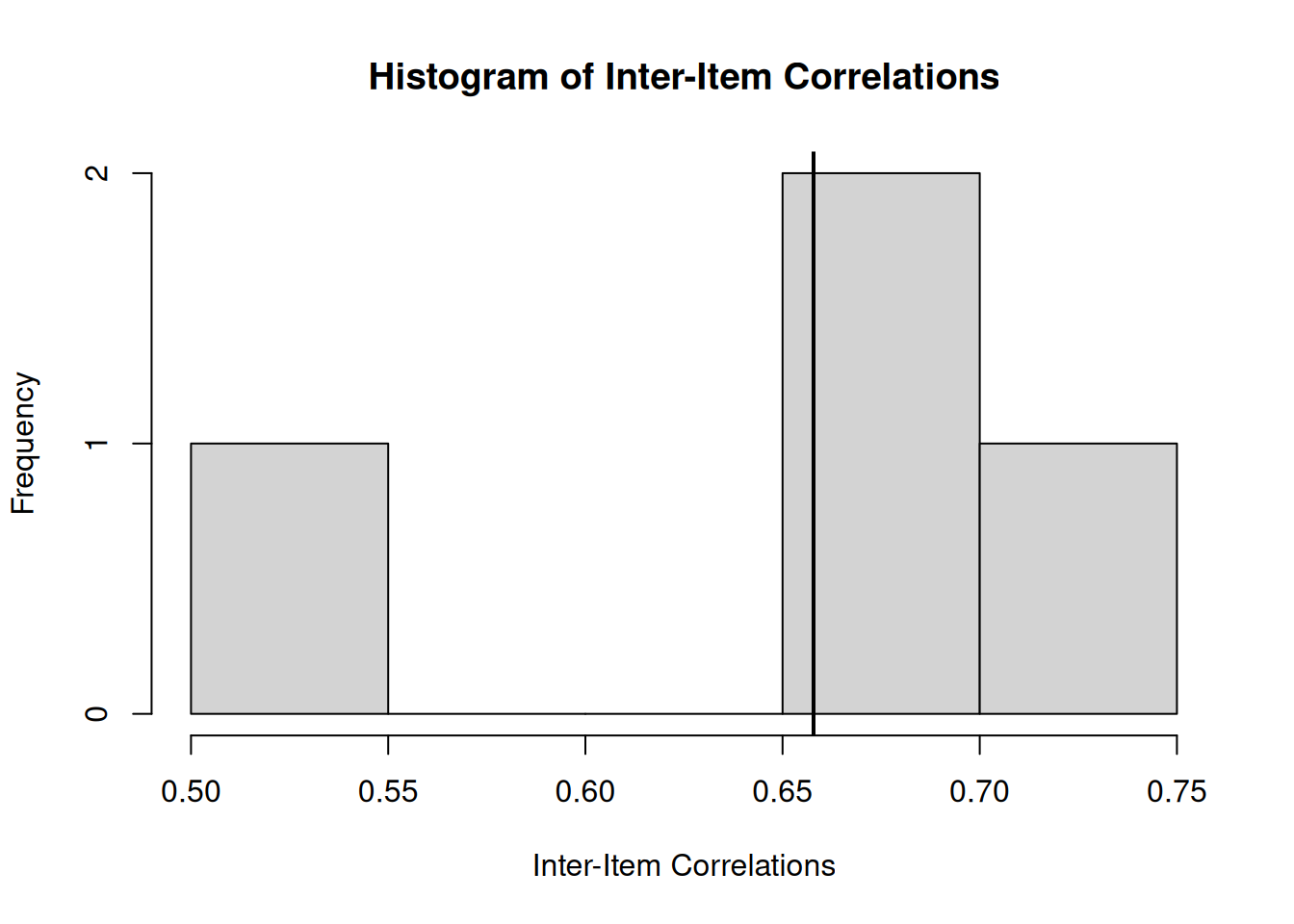
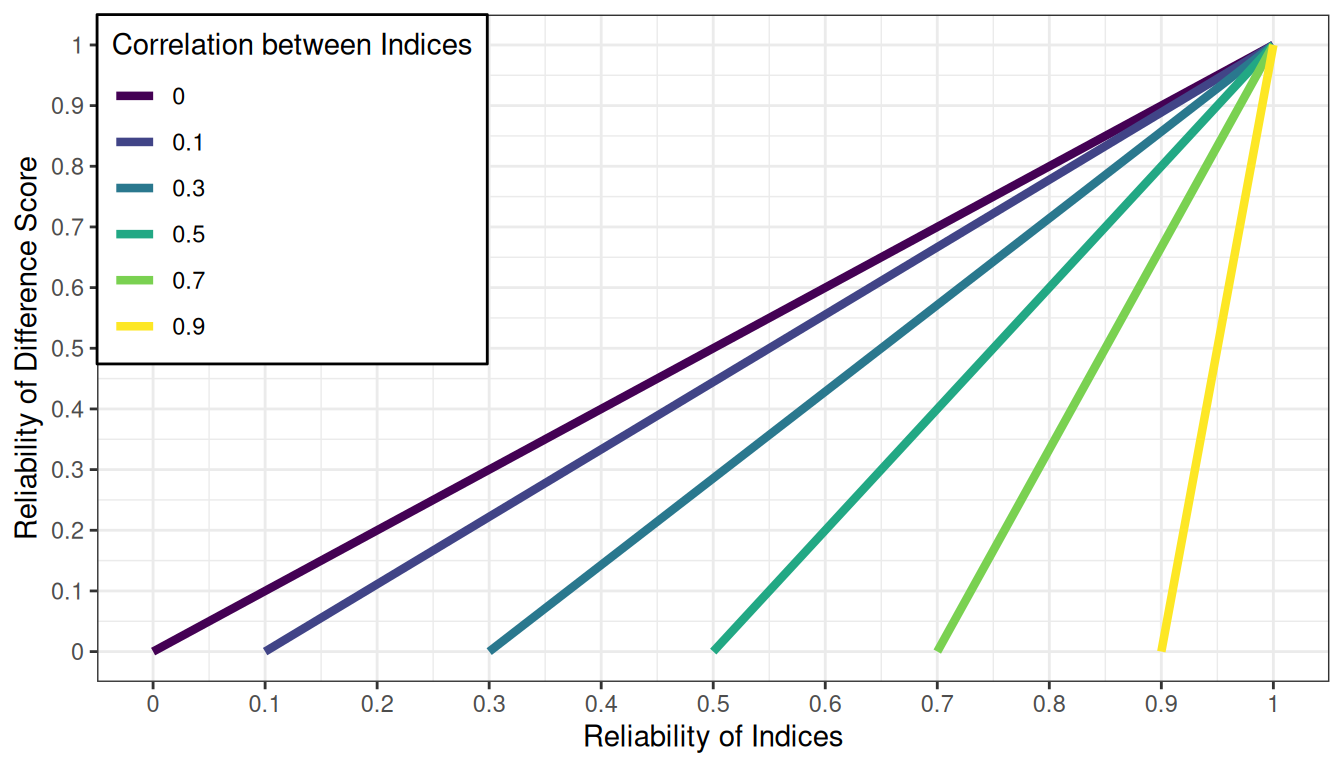
.pardefault <- par(no.readonly = TRUE)
par(mfrow = c(7,3), mar = c(1, 0, 1, 0))
# -1.0
plot(correlations$criterion, correlations$v1, xaxt = "n", yaxt = "n", xlab = "" , ylab = "",
main = substitute(paste(italic(r), " = ", x, sep = ""), list(x = round(cor.test(x = correlations$criterion, y = correlations$v1)$estimate, 2))))
abline(lm(v1 ~ criterion, data = correlations), col = "black")
lines(lowess(correlations$criterion, correlations$v1), col = "red")
# -.9
plot(correlations$criterion, correlations$v2, xaxt = "n", yaxt = "n", xlab = "" , ylab = "",
main = substitute(paste(italic(r), " = ", x, sep = ""), list(x = round(cor.test(x = correlations$criterion, y = correlations$v2)$estimate, 2))))
abline(lm(v2 ~ criterion, data = correlations), col = "black")
lines(lowess(correlations$criterion, correlations$v2), col = "red")
# -.8
plot(correlations$criterion, correlations$v3, xaxt = "n", yaxt = "n", xlab = "" , ylab = "",
main = substitute(paste(italic(r), " = ", x, sep = ""), list(x = round(cor.test(x = correlations$criterion, y = correlations$v3)$estimate, 2))))
abline(lm(v3 ~ criterion, data = correlations), col = "black")
lines(lowess(correlations$criterion, correlations$v3), col = "red")
# -.7
plot(correlations$criterion, correlations$v4, xaxt = "n", yaxt = "n", xlab = "" , ylab = "",
main = substitute(paste(italic(r), " = ", x, sep = ""), list(x = round(cor.test(x = correlations$criterion, y = correlations$v4)$estimate, 2))))
abline(lm(v4 ~ criterion, data = correlations), col = "black")
lines(lowess(correlations$criterion, correlations$v4), col = "red")
# -.6
plot(correlations$criterion, correlations$v5, xaxt = "n", yaxt = "n", xlab = "" , ylab = "",
main = substitute(paste(italic(r), " = ", x, sep = ""), list(x = round(cor.test(x = correlations$criterion, y = correlations$v5)$estimate, 2))))
abline(lm(v5 ~ criterion, data = correlations), col = "black")
lines(lowess(correlations$criterion, correlations$v5), col = "red")
# -.5
plot(correlations$criterion, correlations$v6, xaxt = "n", yaxt = "n", xlab = "" , ylab = "",
main = substitute(paste(italic(r), " = ", x, sep = ""), list(x = round(cor.test(x = correlations$criterion, y = correlations$v6)$estimate, 2))))
abline(lm(v6 ~ criterion, data = correlations), col = "black")
lines(lowess(correlations$criterion, correlations$v6), col = "red")
# -.4
plot(correlations$criterion, correlations$v7, xaxt = "n", yaxt = "n", xlab = "" , ylab = "",
main = substitute(paste(italic(r), " = ", x, sep = ""), list(x = round(cor.test(x = correlations$criterion, y = correlations$v7)$estimate, 2))))
abline(lm(v7 ~ criterion, data = correlations), col = "black")
lines(lowess(correlations$criterion, correlations$v7), col = "red")
# -.3
plot(correlations$criterion, correlations$v8, xaxt = "n", yaxt = "n", xlab = "" , ylab = "",
main = substitute(paste(italic(r), " = ", x, sep = ""), list(x = round(cor.test(x = correlations$criterion, y = correlations$v8)$estimate, 2))))
abline(lm(v8 ~ criterion, data = correlations), col = "black")
lines(lowess(correlations$criterion, correlations$v8), col = "red")
# -.2
plot(correlations$criterion, correlations$v9, xaxt = "n", yaxt = "n", xlab = "" , ylab = "",
main = substitute(paste(italic(r), " = ", x, sep = ""), list(x = round(cor.test(x = correlations$criterion, y = correlations$v9)$estimate, 2))))
abline(lm(v9 ~ criterion, data = correlations), col = "black")
lines(lowess(correlations$criterion, correlations$v9), col = "red")
# -.1
plot(correlations$criterion, correlations$v10, xaxt = "n", yaxt = "n", xlab = "" , ylab = "",
main = substitute(paste(italic(r), " = ", x, sep = ""), list(x = round(cor.test(x = correlations$criterion, y = correlations$v10)$estimate, 2))))
abline(lm(v10 ~ criterion, data = correlations), col = "black")
lines(lowess(correlations$criterion, correlations$v10), col = "red")
# 0.0
plot(correlations$criterion, correlations$v11, xaxt = "n", yaxt = "n", xlab = "" , ylab = "",
main = substitute(paste(italic(r), " = ", x, sep = ""), list(x = round(cor.test(x = correlations$criterion, y = correlations$v11)$estimate, 2))))
abline(lm(v11 ~ criterion, data = correlations), col = "black")
lines(lowess(correlations$criterion, correlations$v11), col = "red")
# 0.1
plot(correlations$criterion, correlations$v12, xaxt = "n", yaxt = "n", xlab = "" , ylab = "",
main = substitute(paste(italic(r), " = ", x, sep = ""), list(x = round(cor.test(x = correlations$criterion, y = correlations$v12)$estimate, 2))))
abline(lm(v12 ~ criterion, data = correlations), col = "black")
lines(lowess(correlations$criterion, correlations$v12), col = "red")
# 0.2
plot(correlations$criterion, correlations$v13, xaxt = "n", yaxt = "n", xlab = "" , ylab = "",
main = substitute(paste(italic(r), " = ", x, sep = ""), list(x = round(cor.test(x = correlations$criterion, y = correlations$v13)$estimate, 2))))
abline(lm(v13 ~ criterion, data = correlations), col = "black")
lines(lowess(correlations$criterion, correlations$v13), col = "red")
# 0.3
plot(correlations$criterion, correlations$v14, xaxt = "n", yaxt = "n", xlab = "" , ylab = "",
main = substitute(paste(italic(r), " = ", x, sep = ""), list(x = round(cor.test(x = correlations$criterion, y = correlations$v14)$estimate, 2))))
abline(lm(v14 ~ criterion, data = correlations), col = "black")
lines(lowess(correlations$criterion, correlations$v14), col = "red")
# 0.4
plot(correlations$criterion, correlations$v15, xaxt = "n", yaxt = "n", xlab = "" , ylab = "",
main = substitute(paste(italic(r), " = ", x, sep = ""), list(x = round(cor.test(x = correlations$criterion, y = correlations$v15)$estimate, 2))))
abline(lm(v15 ~ criterion, data = correlations), col = "black")
lines(lowess(correlations$criterion, correlations$v15), col = "red")
# 0.5
plot(correlations$criterion, correlations$v16, xaxt = "n", yaxt = "n", xlab = "" , ylab = "",
main = substitute(paste(italic(r), " = ", x, sep = ""), list(x = round(cor.test(x = correlations$criterion, y = correlations$v16)$estimate, 2))))
abline(lm(v16 ~ criterion, data = correlations), col = "black")
lines(lowess(correlations$criterion, correlations$v16), col = "red")
# 0.6
plot(correlations$criterion, correlations$v17, xaxt = "n", yaxt = "n", xlab = "" , ylab = "",
main = substitute(paste(italic(r), " = ", x, sep = ""), list(x = round(cor.test(x = correlations$criterion, y = correlations$v17)$estimate, 2))))
abline(lm(v17 ~ criterion, data = correlations), col = "black")
lines(lowess(correlations$criterion, correlations$v17), col = "red")
# 0.7
plot(correlations$criterion, correlations$v18, xaxt = "n", yaxt = "n", xlab = "" , ylab = "",
main = substitute(paste(italic(r), " = ", x, sep = ""), list(x = round(cor.test(x = correlations$criterion, y = correlations$v18)$estimate, 2))))
abline(lm(v18 ~ criterion, data = correlations), col = "black")
lines(lowess(correlations$criterion, correlations$v18), col = "red")
# 0.8
plot(correlations$criterion, correlations$v19, xaxt = "n", yaxt = "n", xlab = "" , ylab = "",
main = substitute(paste(italic(r), " = ", x, sep = ""), list(x = round(cor.test(x = correlations$criterion, y = correlations$v19)$estimate, 2))))
abline(lm(v19 ~ criterion, data = correlations), col = "black")
lines(lowess(correlations$criterion, correlations$v19), col = "red")
# 0.9
plot(correlations$criterion, correlations$v20, xaxt = "n", yaxt = "n", xlab = "" , ylab = "",
main = substitute(paste(italic(r), " = ", x, sep = ""), list(x = round(cor.test(x = correlations$criterion, y = correlations$v20)$estimate, 2))))
abline(lm(v20 ~ criterion, data = correlations), col = "black")
lines(lowess(correlations$criterion, correlations$v20), col = "red")
# 1.0
plot(correlations$criterion, correlations$v21, xaxt = "n", yaxt = "n", xlab = "" , ylab = "",
main = substitute(paste(italic(r), " = ", x, sep = ""), list(x = round(cor.test(x = correlations$criterion, y = correlations$v21)$estimate, 2))))
abline(lm(v21 ~ criterion, data = correlations), col = "black")
lines(lowess(correlations$criterion, correlations$v21), col = "red")
par(.pardefault)